
神経科学と生成系AIの共進化

脳で直接やりとりする技術は、神経科学では以前から知られています。
以前にも、人気ゲームFortniteを脳で操作できるニュースを紹介しました。
他にも、脳内で文字を書く実験も行われています。
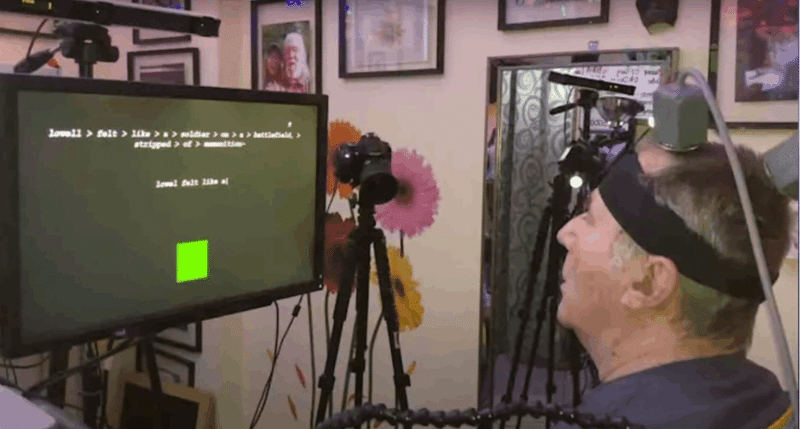
これらが表すように、脳内の電気信号をより精緻に解読できる技術が進化しているわけですが、より豊かな情報である「映像」も同じく研究進化が進んでいます。
2022年に日本の研究グループが興味深い発表を行っています。
ようは、
fMRIで脳内信号を読み取って、生成系AIを使った新たなフレームワークを駆使することで、脳内映像に近いものが再現出来た、
という話です。
英語記事だけだと読みにくいので、もう少し砕いて書いておきますが、何より論文内画像をご覧ください。

なかなかぞっとするほどの再現率だと思いませんか?
実は近いことは10年以上前から世界中で研究は進められていました。私が当時見てびっくりしたのは下記の米国研究グループの成果です。
これも、ぜひ一度は再現能力を見てほしいですが、今回の日本の研究グループは質としては凌駕しています。(比較したいわけではないです)
今回の研究は、構造としては似ています。
ざっくりいえばfMRIという計測装置を使って脳内信号を読み取って計算モデルと符号させる、というやり方です。
その計算モデルに、話題の「生成系AI」の1つ「Stable Diffusion」を採用した点です。勿論それをデータ特性によってチューニングする方法も提示しているので、そんな安易なものではないです。
どうしても最近話題なのはChatGPTですが、これは比較的文字を解釈して生成するのが得意です。(細かくはその元エンジンのGPT3であれば画像生成も出来ますが)
そして両者の長所をうまく組み合わせて、ゲームのRPGを開発しようという試みも日本で進められています。
画像生成系AIとしては、Dall-Eが早期から話題になりましたが、これも動作原理は同じです。
これらの原理はDiffusion Model(あえて訳せば「拡散モデル」)と呼ばれます。Stable Diffusionと名付けられているのは、このモデル計算を効率的(安定的)に行うことによります。
今回の学習の流れは下記のように提示されています。
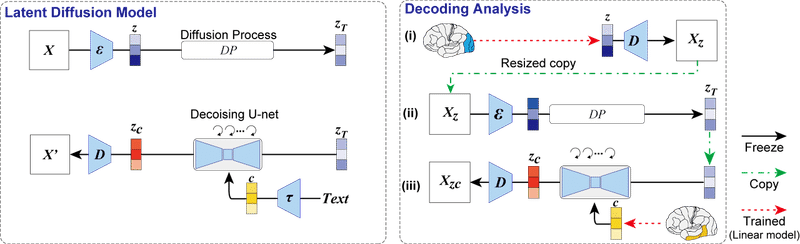
これだけだと分かりにくいですが、今回の論文の鍵は、脳内データのパターンから最適なDMを提示する方法論にあります。
逆にそれがないと、ある意味手動も交えたチューニング作業が発生します。
いずれにしても、fMRIはほぼリアルタイムに脳内データを取得できるので、こちらもよりお手軽(廉価・小型化・モジュール化(処理はサーバで))になっていくと、冗談抜きで一般家庭で夢をTVで再現できる日が遠くないかもしれませんね。
それが幸せかどうかはさておきとして。。。
この記事が気に入ったらサポートをしてみませんか?