Neuromatch Academy 2021(US時間)の体験談(Week3編)

みなさんこんにちは!
これまでの記事では、神経科学に関する夏期集中講座であるNeuromatch Academy 2021の概要と参加登録方法、またWeek1・Week2での講座内容に関してまとめました。
今日は最後の週、Week3の内容についてまとめていきます!
ちなみに、これまで同様、全ての学習教材は以下のwebページ内で公開をされています。
11日目:ベイズ的意思決定
11日目は、推論と意思決定を行うためのベイズ的なアプローチについて学びます。ベイズ理論は、神経科学で用いられている様々なモデルの基礎となっており、またベイズ統計学の基盤でもあります。
ベイズ的なアプローチは、私たちが、事前知識(prior)と観測した情報(observation)に基づいて、どのように知識を更新していくのかを定義する手法として用いることができます。そして、特に重要なのは、ベイズ的なアプローチでは、不確かさが明示的に表現されているということです。私たちが生きる世界では、常に全ての情報を観測することは難しく、また観測された情報も多くのノイズを含むため、不確かさが広く存在しています。ベイズ的意思決定では、その不確かさを考慮した上で、価値を最適化する行動をするための意思決定戦略が考えられます。
このチュートリアルでは、具体的な例を用いながら、このベイズ的なアプローチの数学的な考え方と、それらをどう実際の問題に適応することができるのかを学んでいきます。
Binary hidden stateを持つベイズ (離散)
・ここでは、離散的な状態を持つ場合におけるベイズ的アプローチについて
取り扱う
・具体的な例として、魚群が池の右側にいるのか、左側にいるのかを推測す
るような問題を考える (参考)
・この例では、魚群の実際の位置がHidden stateとして考えられ、それが右
側なのか、左側なのかを推測する問題となる
・ベイズでは、観測された結果が、あるHidden state下において起こりう
る確率のことをLikelihoodと呼ぶ
・ここで扱っている例では、例えば一定期間誰かが釣りをし、どれだけ魚を
釣り上げることができたかを観察していた後で、魚群がどちらにいると
思うかを表す確率のこと
・一方で、もし私たちがすでに何年とその釣り場で釣った経験を持ってお
り、魚群が大体いつも左側にいることを知っていた場合、観測に基づく
Likelihoodではなく、事前知識(Prior)に基づいて判断をするかもしれない
・ベイズでは、LikelihoodとPriorに基づいて、事後確率(Posterior)が計算さ
れる
・この例だと得られた結果と事前知識に基づいて、魚がどちらにどのくらい
の確率でいると信じるかが事後確率(Posterior)となる
・Posteriorは、数式では以下のように表現される
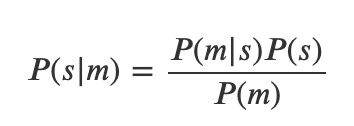
P(s|m):Posterior
P(m|s):Likelihood
P(s):Prior
P(m):Probability of the measurement (Posteriorを正規化するための定数項)
・本チュートリアル内では、Posteriorを実際に計算するための計算問題と、
それを実装するためのコード、またPrior、Likelihood、Posteriorがどのよ
うに関連しているかを理解するためのデモが紹介されている (参考)
Continuous hidden stateを持つベイズ (連続)
・連続的な分布を扱う際のベイズ的アプローチについて考える
・具体的な例として、ネコの宇宙飛行士が宇宙空間を動き回り、同じく宇宙
にいるネズミを捕まえることを考える
・但し、ネコは自分で動きをコントロールすることはできず、地球にいるヒ
トがネコの動きをコントロールする必要がある
・ここでは、ネコを適切に動かすために、地球のヒトがネコの正しい位置
(連続値)を推測する問題を、ベイズを用いて考える
・チュートルアル内では、連続値を扱う際によく用いられる正規分布と、連
続値を扱う際に用いられる損失関数について詳細が紹介されている (参考)
・LikelihoodとPriorの両方が正規分布に従うと想定すると、ベイズの定理は
以下のように表現される

・上記式では、Posteriorは、LikelihoodとPriorの加重平均(重みはそれぞれが
持つ情報量)になっていると考えられる。例えば、もしPriorの分散が小さ
ければ(つまり情報量が大きければ)、Posteriorの平均値はよりPriorの平均
値の方に引っ張られる
・情報量:分散の逆数
・本チュートリアルでは、PriorやLikelihoodの分布が正規分布以外の場合
や、様々な損失関数を使った場合に、どのようにPosteriorが変化するかを
確かめることができるシミュレーション用のコードが紹介されている
(参考)
12日目:隠れマルコフモデル (Hidden Markov Models (HMMs))
12日目は、データの流れから世界の物事(特に明示的ではない物事, latent variable)を推測することができる隠れマルコフモデル(HMM)について学びます。HMMは、神経科学の分野で広く使われているモデルです。例えば、HMMは、蛍光画像(fluorescence images)から神経活動を推測するなどのデータ解析に用いられています。
ここでは具体例として、11日目にも用いた魚群の位置を推測する例と、ネコの宇宙飛行士が宇宙空間を動き回る例を引き続き用いて考えます。そのような具体例を通じて、観察した情報に基づいて、隠れた状態(latent state)がどのように変化しているかを推測ためのアルゴリズムを理解し、またその実装方法を学んでいきます。
Binary hidden stateを持つ隠れマルコフモデル (離散)
・まずは、状態が2値で表されるような離散的な状態を持つ場合における
HMMについて考える
・また、ベイズモデルを学習した際に用いた例とは異なり、ここでは、複数
の情報を時間経過とともに観測することを考える
・時間経過とともに観測される情報をもとに、その時の状態(state)を推論を
するためのモデルとしてここでは、Sequential Probability Ratio Test
(SPRT, 逐次確率比検定)について学んでいく
Sequential Probability Ratio Test (逐次確率比検定)とは
・逐次確率比検定は、2つの仮説のうちどちらがより可能性が高いかを判定
するために用いられる尤度比検定(likelihood ratio test)である
・尤度比検定は、その名の通り尤度の比を計算する検定である
・複数の観測が得られる場合、尤度は、二値(binary, 例:±1)の状態それぞれ
がhidden stateだった場合に、この観測が得られる確率と考えることがで
きる
・つまり、p(複数の観測 | 状態 = 1) と p(複数の観測 | 状態 = -1) のこと
・上記は、観測の集合をm、状態をsと置き、さらにそれのLogをとると、以
下のような形で表現される。このL_TはLog Likelihood Ratio(対数尤度比)
と呼ばれる
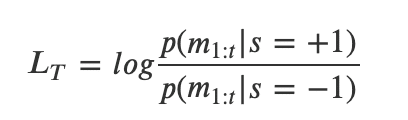
・ここで、得られた観測が独立同一分布に従うと仮定すると、それぞれの状
態(+1 or -1)で測定値mを得る確率は、その状態下で一つ一つの測定値m_t
を得る確率の積に等しいと考えることができ、以下のように書き換えるこ
とができる
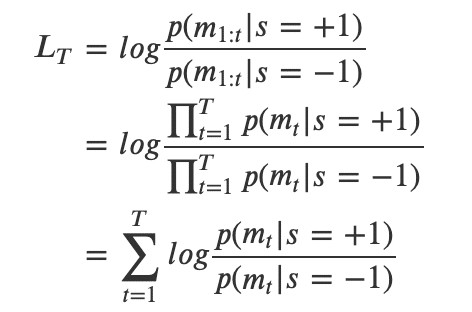
・この式から、全観測に基づいたLog Likelihood Ratio L_Tを得るためには、
各時間ステップtでのLog Likelihood Ratioを合計すればよいことがわかる
・SPRTでは、L_Tが正の値であれば、状態が+1である可能性が高いと考え、
L_Tが負の値であれば、状態が-1である可能性が高いと考えられる
・本チュートリアル内では、SPRTを用いたシミュレーションを行うための
コードが紹介されている (参考)
・また、
- SPRTとDrift Diffusion Model (DDF, ドリフト拡散モデル)の繋がり
- DDFを用いたスピードと正確性のトレードオフのシミュレーション
についても紹介されている
状態が動的に変化する場合のBinary隠れマルコフモデル
・逐次確率比検定の紹介では、状態は時間とともに変化しない例を扱った
・ここでは、状態も時間と共に変化する場合を考える
・また、状態の時間の変化がマルコフ性に基づいている場合を考える
・マルコフ性とは、時刻tにどの状態であるかを表す確率が、時刻t-1の状態
によって全て決まること
・つまり、時刻tにおける状態は、時刻t-1における状態のみに依存する
・時刻tにおける状態s_tの確率は、以下のような行列を用いてまとめること
ができる
- 左上: 時刻t-1における状態が+1だった時に、時刻tの状態が+1である確率
- 右上: 時刻t-1における状態が+1だった時に、時刻tの状態が-1である確率
- 左下: 時刻t-1における状態が-1だった時に、時刻tの状態が+1である確率
- 右下: 時刻t-1における状態が-1だった時に、時刻tの状態が-1である確率
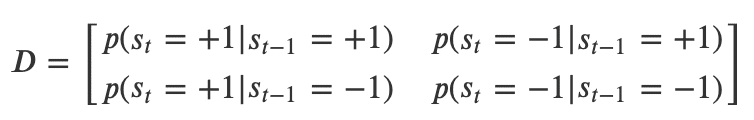
・ここで、ある時刻tにおける状態の確率を以下のようなベクトルで表現する
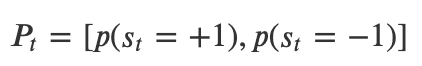
・すると、ある時刻tにおける状態の確率P_tは、前の時刻t-1における状態の
確率と、その状態からそれぞれの状態への遷移確率Dの積として以下のよ
うに表現することができる
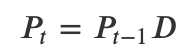
・このような形で表現できるモデルのことをHidden Markov Model(HMM)と
呼ぶ
・また、特に状態がBinaryの場合、Binary Hidden Markov Modelと呼ばれる
・本チュートリアルでは、Binary HMMを用いたシミュレーションを行うた
めのコードが紹介されている (参考)
・また、Binary HMMを用いて未来の状態を推測するためのコードも紹介さ
れており、この推測におけるノイズと遷移行列の確率の影響に関する説明
もされている
Continuous hidden stateを持つ隠れマルコフモデル (連続)
・ここでは、Hidden stateが連続値をとる場合について考える
・状態が連続値である場合に用いられる推測モデルとして特に
カルマンフィルタ(Kalman Filter)について学んでいく
・具体的な例として、以前も用いたネコの宇宙飛行士が宇宙空間を動き回る
例を考える
・特に、モデルを用いてネコの正しい位置を推測したいが、観測されるネコ
の位置情報がノイズを含んでいる場合を考える
・カルマンフィルターは,時間的変化を表す数学的モデルと入力される観測
値を用いて、時間の経過とともに事後確率分布(posterior)を再帰的に推定
する
・この動的な事後分布の推定により、新しい測定値が到着するたびに、ネコ
の位置に関する推測を改善することができる
・また、その推定値の平均値は、各時間ステップにおけるネコの実際の位置
を計算するための最良の推定値となる
・数式も含めたカルマンフィルタの詳細はチュートリアル内で説明をされて
いるが、大きくは以下のようなステップを経て、時刻tにおける推測値を更
新していく
step1:時刻t-1における事後分布を時刻tにおける事前分布(prior)とする
step2:時刻tにおける事前分布と、時刻tにおける観測値に基づく尤度
(likelihood)の積をとる (ベイズ)
step3:事後分布の分散を求め、時刻tにおける事前分布と尤度から得ら
れた情報量(分散の逆数)をそれまでに得られていた情報量に加え
る。新たな情報量の逆数を取り、事後分布の分散を計算する
step4:事後分布における平均を求めるために、時刻tにおける事前分布と
尤度から得られたそれぞれの平均値の加重平均を計算する。ここ
での重さは、事前分布、尤度それぞれが持っている情報量。
step5:step1-4を繰り返す
13日目:最適化コントロール (Optimal Control)
これまでは、観測した情報をもとに、どのようにしてHidden stateを推測するかを学んできました。13日目は、その推測された結果をもとに、どのように得られる効果(Utility)を最大化するための行動を選択できるかを学んでいきます。ここでの学習目標は、知識を使って良い行動を選択するためのアルゴリズムを理解し、実装することです。
Binary hidden stateを持つ場合の最適化コントロール
・これまでのチュートリアルでも使ってきた、魚釣りの例を用いて考える
・これまでのチュートリアルで、どのように魚群が左側にいるのか右側にい
るのかを推測できるのかを学んできた
・ここでは、その情報をもとに、どのように自分が釣りをする場所を変え
て、そこで得られた情報をもとに、どのように魚群の位置の推測を更新し
ていくかを学ぶ
例のより具体的な設定
・魚群がいる場所で釣りをすると、高い確率q_highで魚を釣り上げることが
できる。一方で、魚群がいない場所では、低い確率q_lowでしか魚を釣り
上げることができない
・また、魚群のいる場所は、魚群が同じ場所に滞在する確率をp_stayと表す
と、以下のような確率で変化すると表現できる
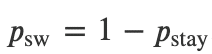
・同じ場所で釣りを引き続き行う場合は、何もコストがかからないが、場所
を変える場合はコストCがかかる
・ポリシー(policy):それぞれの状況においてどのような行動を取るべきか
を定義しているもの
・この例では、状況は、実際に今釣りをしている場所(右or左)と、どちらに
魚群がいると信じているか(belief)によって決まる
・最適化コントロールの枠組みでは、ここでのbeliefは、過去のすべての観
測値(魚が釣れたかどうか)が与えられたときの、現在の魚の位置に関する
事後確率(posterior)であると考えることができ、以下のように書き表せる

m:それぞれの時刻における観測値
a:それぞれの時刻における行動 (stay or switch)
・最終的には、beliefに対する閾値によってpolicyを決める。つまり、自分が
いるサイドに魚群がいると考えるbeliefがある閾値θを下回った場合、別の
サイドに釣り場を変更する
・このpolicyでは、正しい閾値θを設定することができれば、最適な行動を
取ることができる
・このチュートリアルでは、魚群の位置が変化しない場合、する場合それぞ
れにおけるシミュレーションを行うためのコードと、釣り場所を選ぶため
の最適なpolicyを価値関数(value function)に基づいて見つけるためのコー
ドが紹介されている(参考)
Continuous hidden stateを持つ場合の最適化コントロール
・ここでは、ネコが宇宙でネズミを捕まえようと、ジェットパック(空気を
噴出して移動する機器)を使って移動する例を考える
・まずはゴールの位置 g(t)、つまりネズミの位置が一定である場合を考える
・また、ネコの位置をこのシステムの状態であるs(t)として考える
・次の時間ステップs(t+1)での状態は、現在の状態s(t)の線形関数として表現
されるとする
・さらに、状態sはガウシアンノイズ(w_t)の影響を受ける
・つまり、state(t)である行動a (ジェットパックへの入力の大きさ)を取る
と、次の状態state(t+1)は、B*a_t のような線形関数で表現される
・このチュートリアルでは、ゴールの位置gに辿り着くことができるよう、
行動aを設計していく問題を考える
・この問題は式で表現すると以下のようになる
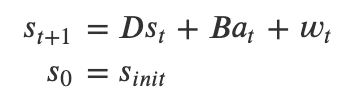
t : タイムステップ (1からTの値を取る)
s_t: 時刻tの状態
a_t: 時刻tの行動
w_t: 時刻tのガウシアンノイズ
D & B: 線形動的システムのパラメーター
・このチュートリアルでは、上記のモデルでゴールにたどり着くための最適
な行動a_tを見つけていくために、Open-loop control・Closed-loop
controlを用いたシミュレーションを行うためのコードが紹介されている
(参考)
・上記のシミュレーションでは、最適な行動a(ジェットパックへの入力の大
きさ)が非常に大きくなる場合がある
・しかし、例えば、ジェットパックに大きな入力を与えると爆発する恐れが
ある場合、入力の大きさはある一定量内に抑える必要がある
・このような制約がある上で行動を最適化していくためにLinear quadratic
regulator (LQR)を用いることができる
・このチュートリアルでは、LQRを用いて最適なアクションを求めていくた
めのサンプルコードに加え、ゴールの位置が変わる場合におけるLQRの応
用コードも紹介されている (参照)
・LQRは、時刻tにおける状態が完全に観測される場合に用いることができ
る。一方で、状態が完全には観測できない場合、観測におけるノイズも考
慮するためにLinear Quadratic Gaussian(LQG)が用いられる
14日目:強化学習 (Reinforcement Learning)
14日目は、神経科学分野で最も広く使われているモデルの一つである強化学習について学びます。強化学習は、動物やエージェント(agent)が各状態(state)に応じて報酬(reward)を受け取ることで、各状態の価値や、各状態の中で取りうる行動を学習するという学習問題を解決するためのフレームワークです。強化学習は、元々は動物行動の研究から設計され、後にそのモデル内で用いられている変数が実際に人間や動物の脳でも観察されたことから妥当性が検証されました。また、現在では強化学習は神経科学に限らず、経済学・心理学・コンピューターサイエンス等様々な分野でも用いられています。
未来の状態の価値をどのように経験から学ぶのか
・ここでは、Temporal Difference(TD)学習を用いて状態値関数を推定する
方法を学び、条件刺激(Conditioned Stimulus, CS)と無条件刺激
(Unconditioned Stimulus)のそれぞれが提示されたときのTDエラーの違い
を理解する
・また、報酬の大きさの分散やその他のパラメータの変化がどのように報酬
予測誤差(Reward Prediction Error, RPE)に影響するのかも学ぶ
・TD学習は、ある状態において予期していた将来の報酬と実際に得られた報
酬の差分を計算し、その差分(TDエラー)に基づいて報酬の予測を更新する
・TDエラーの計算式は以下のように表現できる
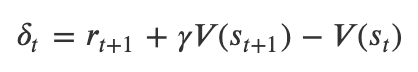
δ:TDエラー
r_t+1:時刻t+1で得られた報酬
γ:割引率 (0 <= γ <= 1)
V(s_t):時刻tにおける状態で得られる報酬量の予測値
・また、上記式を用いて計算されたTDエラーをもとに、TD学習ではある状
態における報酬量の予測値を以下の式に基づいて更新する
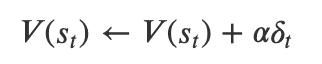
α:学習率 (0 <= α <= 1)
・条件刺激(Conditioned Stimulus, CS)の例:パブロフの実験で、犬がベルを
鳴らすとその条件に反応して唾液が出る
・無条件刺激(Unconditioned Stimulus)の例:美味しそうな食べ物の匂いが
すると無条件に唾液が出る
・TD学習モデルを学習し始めた際は、報酬がもらえる状態(無条件刺激)だけ
が非常に高い状態価値を持っている
・一方で、学習が進むにつれて、報酬に至るまでのプロセスにあたるような
状態(条件刺激)における価値も徐々に上がっていく
・このようなそれぞれの状態価値を報酬に基づいて更新する役割を脳内では
ドーパミンが担っていると考えられている
・本チュートリアルでは、TD学習モデルを実際に実装するためのコードと、
学習率や割引率、また報酬の大きさによってどのように学習結果が変わる
のかをシミュレーションするためのコードが紹介されている(参考)
探索(exploration)と利用(exploitation)のジレンマとは?
・k個の選択肢から一つを選択するという行動を1000回以上繰り返すような
問題を考える
・それぞれの選択肢には報酬が紐づいており、繰り返し選択をしていく中
で、繰り返し全体での合計の報酬量を最大化したい
・つまり、最も高い報酬量に紐づいている選択肢を見つけ、その選択肢をで
きるだけ多くの回数選択できるようにしたい
・このような問題は、k-armed bandit problemと呼ばれる
・k-armed bandit problemを考える際に考えなければならないのが、
探索と利用のジレンマである
・探索と利用のジレンマ:今の時点で最大の報酬を得ることができる選択を
するべきか、それともより良い選択肢を見つけるために、まだ情報が少な
い選択肢を探索するべきか。今見えている選択肢だけで選択をすると、他
に存在するより良い選択肢を見逃してしまう可能性がある。一方で、探索
ばかりすると、探索期間中低い報酬しか得られないかもしれないという
リスクがある。
・報酬を最大化するための最適な戦略(policy)を見つけるためには、探索と
利用の適切なバランスを取ることが重要である
・本チュートリアルでは、このようなバランスを取るための一つの手法であ
るε-greedy法の実装方法と、その中のパラメーターを変化させた際のモデ
ルの動きをシミュレーションするためのコードが紹介されている(参考)
経験からどのように将来の行動価値を効率的に学ぶのか (Q学習)
・より現実的な問題設定では、上記で扱ったk-armed bandit problemのよう
に実行された行動に紐づいた報酬がすぐに得られる問題だけでなく、一つ
一つの行動が将来の先々の報酬に影響を与えるような状況が多く存在する
・このような状況下で意思決定を行うには、各行動の結果将来に期待される
累積の報酬を考えた上で行動を考えていく必要がある
・例えば、ある空間においてゴールにたどり着くような問題を考えると、
エージェントは実際にゴールに辿り着き報酬を得るまでにいくつもの行動
を積み重ねる必要がある
・そのような問題を解く上で用いられる基本的なモデルが、
Q学習(Q-learning)である
・Q学習は、数式では以下のように表現される
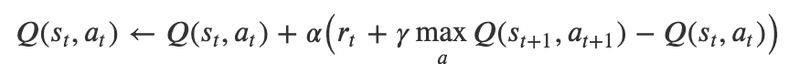
𝑄(𝑠,𝑎):状態sにおける行動aの価値関数
𝛼:学習率
𝑟:報酬
𝛾:割引率
・Q学習は、エージェントがその先にpolicyに基づいて実際にとった行動
ではなく、状態sから最適と考えられる行動を続けた場合に基づいて価値
関数を計算するため、off-policyな手法として分類される
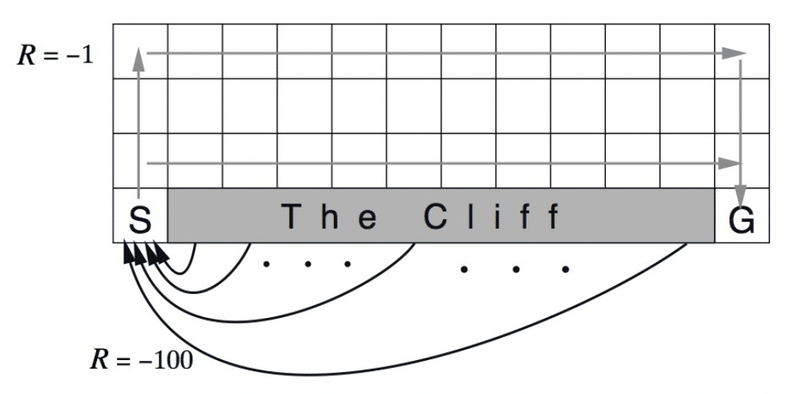
・本チュートリアルでは、Q学習を実装し、以下のようなGrid worlds問題を
解くためのコードが紹介されている (参考)
モデルフリー・モデルベース強化学習とは?
・ここまで扱ってきた強化学習モデルは、経験にのみ基づいて学習を行う
モデルであり、モデルフリー強化学習に分類される
・モデルフリー学習は多くの学習データ(経験)を必要とする
・一方で、モデルベース強化学習とは、世界がどのように動くのかをモデル
として持ち、そのモデルを用いて未経験の状況でも将来を推測する
・モデルベース強化学習の例としてよく使われるモデルの一つに
Dyna-Qが挙げられる
・Dyna-Qエージェントは、行動、学習に加えて、計画を行う
・行動、学習においては、Q学習等と同じようなアルゴリズムで動く
・計画においては、Dyna-Qエージェントは世界のモデルに基づいて、
経験をシミュレーションし、そこからも学びを得る
・Dyna-Qにおいて、世界のモデルは、単純に過去の経験に基づくある状態
から次の状態への遷移確率を記録した大きな行列によって表現される
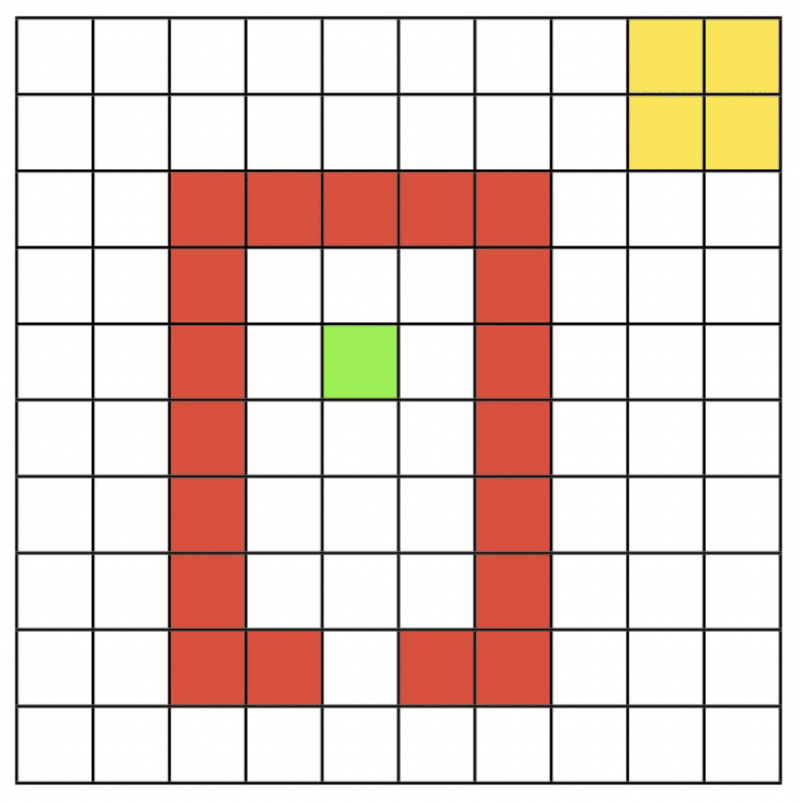
・本チュートリアルでは、Dyna-Qを用いて、以下のような10x10のグリッド
の中で緑のスタート位置から黄色のゴールにたどり着く方法を学ぶモデル
を実装するためのコードが紹介されている
15日目:ネットワークの因果性 (Network causality)
最終日15日目は、因果性について学んでいきます。因果性は、ある変数が他の変数にどのように影響を及ぼすかを問うために使うことができるツールです。因果性は神経科学も含め科学の根幹とも言われるものです。一方で、よく見過ごされてしまっているトピックでもあります。
因果性とは?
・AがBを引き起こすとはどういう意味か?
・介入に基づいた因果性の定義では、AがBを引き起こすとは、
もしAに強制的に何か変化を加えた場合、Bも必ず変わることを意味する
・例として、ニューロンAがニューロンBを発火させるという因果を考える
・この場合、もしニューロンAがニューロンBを発火させるかどうかを知りた
ければ、ニューロンAに刺激を与えた時に、ニューロンBで何が起きるかを
観察する
・これは、数式では以下のように表現される
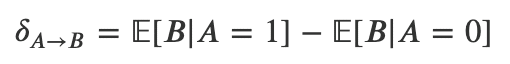
δ_AB:ニューロンAによるニューロンBに対する平均の因果的影響
E[B|A=1]:Aが活動した時のBの活動の期待値
E[B|A=0]:Aが活動しなかった時のBの活動の期待値
・本チュートリアルでは、実際に二つのニューロンの一方を刺激をした際の
もう一方の活動をシミュレーションするためのコードが紹介されている
(参考)
・次に、ここまで紹介したような二つのニューロン間だけではなく、より
大きなニューラルネットワークにおける因果性について考える
・具体例として、N個のニューロンがお互いに繋がり影響し合っている場合
を考える
・それぞれのニューロンの時刻t+1での活動は、時刻tでの他のニューロンの
活動に依存する
・ただし、あるニューロンは、全部のニューロンN個のうち10%の
ニューロンからしか刺激を受け取らないとする
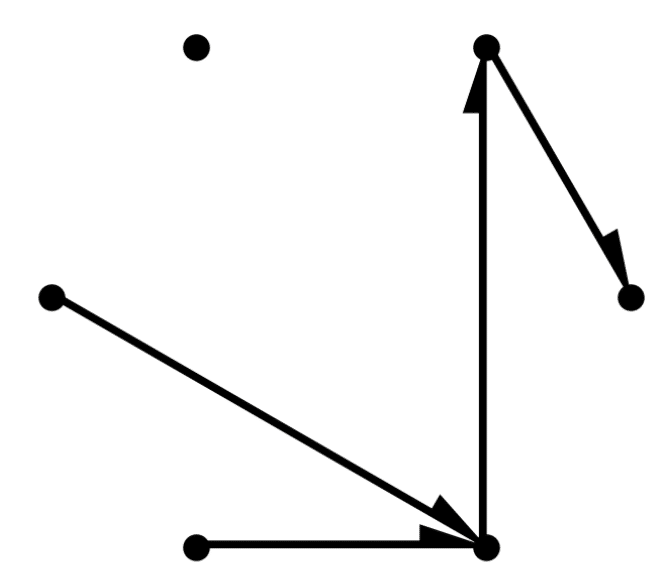
・以下は6個のニューロンでのconnectivityのシミュレーション結果である
・本チュートリアルでは、このようなネットワークに介入し、それに対する
各ニューロンの活動から因果関係を推論するためのコードが紹介されてい
る(参考)
因果を推定するために相関を用いることができるか?
・上記で説明したようなニューロンに直接刺激を送るような操作は、
実際の実験ではなかなか難しい場合が多い
・つまり、観測された神経活動からできることを考える必要がある場合が
多い
・ここでは、そのような観測された神経データを用いて計算された相関が
どのような時は因果の概算値として考えることができ、どのような時は
できないのかを学ぶ
・特に小さなネットワークの場合、相関関係は因果関係と類似する
・以下は、前項で用いられた6個のニューロンによるネットワークの因果性
を相関に基づいて復元した結果である
上図:真のconnectivity
下図:相関に基づいて復元されたconnectivity
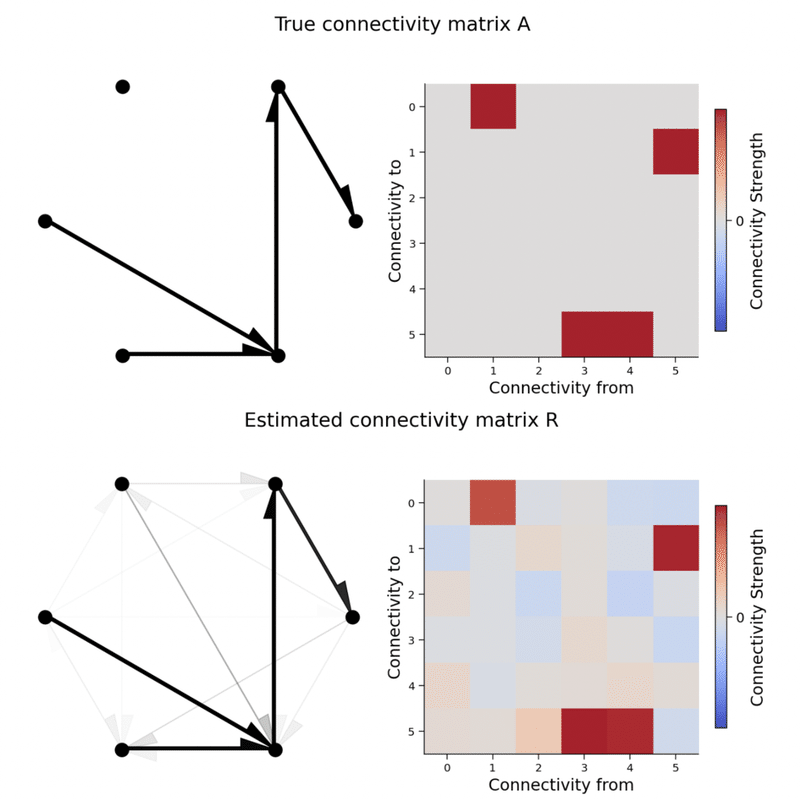
・多少の違いはあるが両者は非常に似ていることがわかる
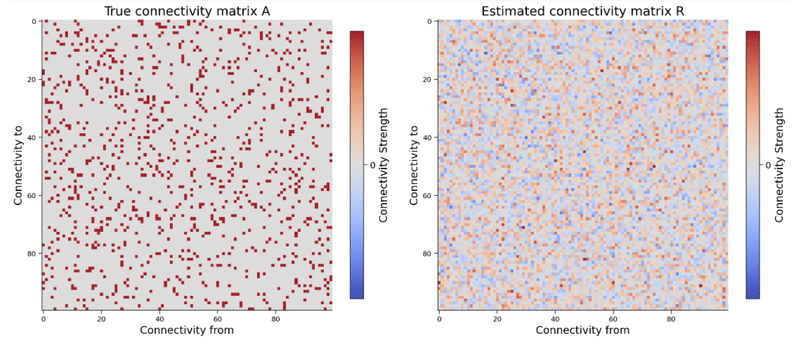
・一方でネットワークが大きくなると、以下の図のように相関は正しい
因果性を見つけることができなくなる (ニューロン100個の場合)
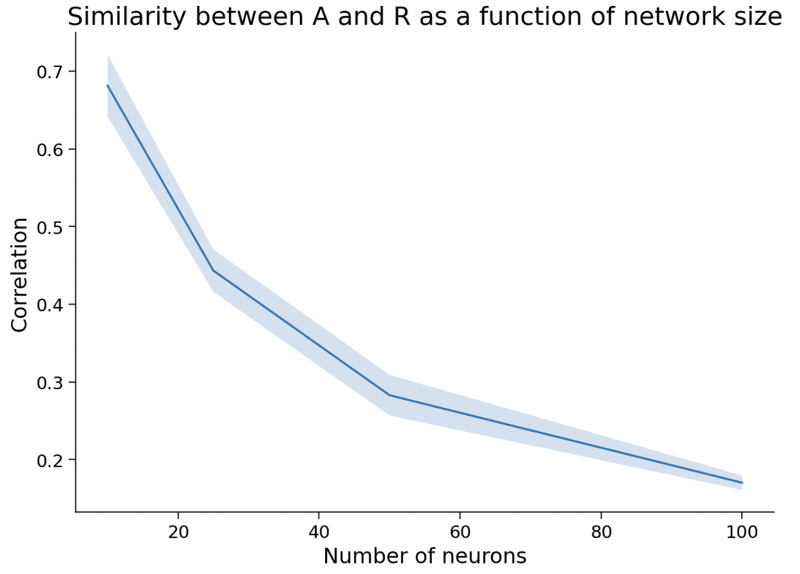
・まとめると、以下の図のように、ニューロンの数が増えるほど、相関と
因果の類似度は下がっていく
回帰モデルを用いて因果を推定する
・観測したデータに基づいて回帰モデルを学習させることで因果関係を推測
するための手法について学ぶ
・一般的に、相関は交絡(confounds)が存在しない場合のみ、因果関係とし
て考えることができる
・但し、以下の三つの条件を満たす場合に限り、交絡があっても回帰モデル
から因果関係を導くことができる
1. 全ての交絡因子を共変量としてモデルに含む
2. 共変量と目的変数の間に同じ数学的形式を想定している
(例:線形、GLM等)
3. 元の変数と目的変数の両方によって引き起こされる共変量は存在しない
・実社会では、また特に脳活動のデータを扱う際には、このような条件を
満たすことは非常に難しい
・本チュートリアルでは、仮想的なデータを用いて、実際に回帰モデルを
用いて因果関係を推定するためのコードが紹介されている(参考)
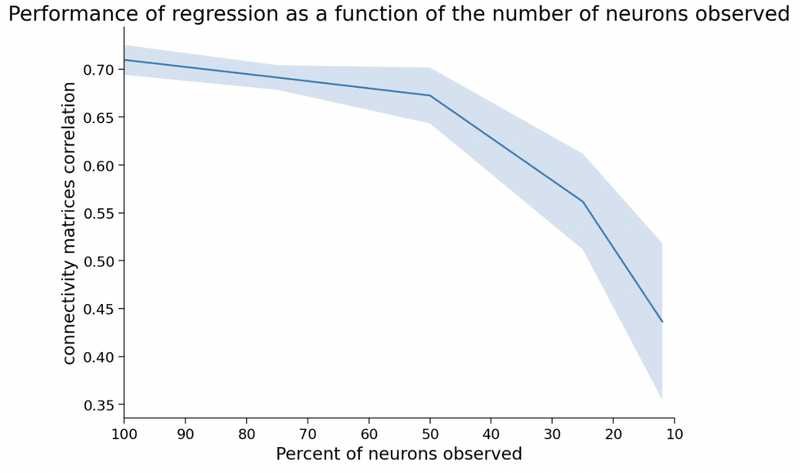
・脳において、全てのニューロンから活動を記録することは困難である。
そして、以下の図に見られるように、全体に対して観測されている
ニューロンの比率が下がるほど、実際の相関関係と回帰によって求められ
た関係は大きく乖離するようになる (omitted variable bias)
操作変数とは?
・以下のような三つの条件を満たす変数を操作変数と呼ぶ
1. 観測可能である
2. 気にしている共変数に影響を与える
3. 結果に共変量を通じてしか影響を与えない (直接的には影響を与えない)
・具体的に理解をするために、妊娠中の喫煙が乳児の出生時体重に及ぼす
影響について推測することを考える
・この両者には相関があると言われているが、多くの交絡が存在するため、
両者の因果関係を単純に評価することは難しい
・そのため、全ての交絡をコントロールすることを考えるのではなく、操作
変数を見つけることを考える
・例えば、各州のタバコに対する税金は上記の三つの条件を満たすため操作
変数と見なすことができる
1. 税金は観測可能である
2. タバコの消費量に影響する
3. 出生時の体重にタバコを介してしか影響しない
・この操作変数を用いて因果関係を推測するには、以下の二つのステップを
実施する
step1:タバコの消費量をタバコの税金で回帰することで求める
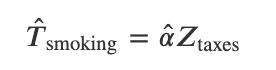
step2:出生時体重をstep1で求めたタバコ消費量で回帰することで求める
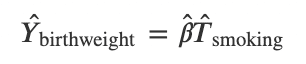
・本チュートリアルでは、この例を実際に実装するコードに加え、神経科学
における例で操作変数を用いるためのコードも紹介されている(参考)
最後に
今日はNeuromatch Academy2021の最終週Week3の内容についてまとめました。Week2と同様こちらもなかなかヘビーでしたね。
これまでの内容も含め、Neuromatch AcademyのComputational Neuroscienceコースは、この分野を広く展望できるようなコースになっていると思います。決してそれぞれのモジュールは深いところまで踏み込んでいる訳ではないですが、これからその分野を学んでいくためのキーワードやキーコンセプトが散りばめられているような印象です。
また、私自身この分野で研究している身として、より深い数学的な理解の重要性は強く感じています。このコースでも多くの数式が出てきましたが、最初はどれも、うっ。。。となります。でもそのような難しさに負けずにしっかりと時間をかけて向き合っていくことが大切なように思います。
ここまで4本に渡って書いてきた内容が、今後Neuromatch Academyを受けることを検討される方や、Computational Neuroscienceに興味を持っている方の少しでも参考になると嬉しいです。
今日は以上です!
この記事が気に入ったらサポートをしてみませんか?