
音声合成・30年の棚卸し

0 はじめに 音声合成について色々と吐き出してみます
エンタメ系の会社で社会人を始めたずいぶん前から、音声合成を使うことにずーっとトライしてきました。この記事では、現段階の集大成として、積み上げたもの、整理できたものをまとめてあります。
音声合成に興味がある方、これから音声合成を使っていく方にとって、物量と時間をかけずにノウハウの一例が分かる、というものになっています。
長文ではありますが、ぜひお役立てください。
ーーーーーーーーー
8ビットのプロセッサでアセンブラで仕込みをしていたころ。今考えれば本当に稚拙な声しか出ませんでした。それでも世の中に声という新しい表現を届けられたことに感動。でも、ディレクターからは「これじゃない」と言われる日々。
それから結構たち、今の環境は「日本国民全員音声合成を使う」という状況にまでなりました。
CPU性能も音声合成技術も向上しましたが、以下の状況変化が大きいと考えています。
・再生できるプラットフォームとしてスマホが個人に行き渡った
・ロボットのサービス的な使われ方の普及
・スマートスピーカーの登場
・ツイッター等のコミュニケーションサービスで音声を扱うようになった
などにより音声合成が活躍する場がどんどん増えているのが要因と考えます。
このように、環境も体験タイミングもかなり行き渡った感があります。しかし、その中身についてはどうでしょう?最初の一回は面白い、特定の場面では使える、などまだまだ限定された状況での利用にとどまっているのではないでしょうか。
使われ方については自分が想像できるバリエーションのまだ入り口、という感覚もあります。
長年執着し続け過ぎてある種のこじらせの度が過ぎているのかもしれません。それでも、過去からの経緯を見て現在を考えると、間違いなく「その先」はあり得る、しかも自分はどうやら「その先」を見ているかもしれない、という考えから、音声合成にまつわる個人的なノウハウの棚卸をここで行いたいと思います。
音声合成とのかかわりで言えば、ほぼ「使用者」でした。短期間開発に関わっていたこともありますが、基本的には常に世の中のためになったり楽しくしたりするサービスやコンテンツを一生懸命考えていたような気がします。
ということで、このコンテンツでは原理や開発に関わることはあまり言及しておりません。使い方特化、とお考え下さい。
ここまでの文章を実際に音声合成で再現したファイルを貼っておきます。
0.5 音声合成と親和性の高い他の技術との関係
様々な場面で「音声によるUI」が発達し、音声合成を組み込んだサービスの形になっています。例えば、スマートスピーカーに対して、音声で命令を与え、答えが返ってきて何かを実行する、という流れを簡単に見てみましょう。
(1)人間が言葉を出す
(2)スマートスピーカーのマイクが人間の言葉を拾う
(3)拾った音声信号を雑音除去等のデジタル処理
(4)処理された信号の言語解析(日本語のルールに基づく文法的な形態素解析)
(5)解析された言葉からキーワードを抽出し、返答用データベースから返答を選択
(6)返答用データベースから選択されたデータを音声合成処理部に送信
(7)音声合成で作成された音声波形をスピーカーに送り、発声
(8)同時に何かを実行(音楽を再生するなど)
![]()
(2)(3)(4)は人間が発声した音を日本語の言葉として理解をするための「音声認識」技術になります。(5)はそれまでの処理で抽出されたキーワードに対応する処理のアクションとなります。ゲームで言えば、Aボタンを押されたらキャラをジャンプさせる、などの内部処理に相当します。(6)がこれから説明する「音声合成」になります。(7)(8)は(5)と同じく、サービス特有の内部処理。
このように、「音声合成」は、いわゆる「音声認識」「動作処理のデータベース」などと組み合わされる形で用いられることもしばしばあり、総合的に良いサービスを作るためには、そういった親和性の高い技術についても理解を深めることで、より良い使い方ができることになります。ここでは、そういった技術にも言及していきたいと思います。
1 音声合成ってどんな技術?
ご存知の人は良くご存じで、そうでもない人は「機械がしゃべるんでしょ?」という感じの、でも、ものすごい昔からある技術です。
最近多くの人が耳にするのは、Youtubeでぶっきらぼうにしゃべる機械っぽい声や、スマホに住んでいる音声アシスタント、スマートスピーカーかもしれません。しかし、色々なところで人知れず使われています。駅のアナウンス、カーナビ、企業の電話応対システム・・・それぞれ、使う「理由」はありますが、今のところ多くは、「人間のアナウンサーでは対応しにくい」ケースに活かされる形が多いようです。
1-1 音声合成の超簡単原理
50音表を思い浮かべてください。「あ」「い」「う」「え」「お」と一つずつ録音しデータを作ったとします。例えば、「青い」という文章に対して、順番に「あ」「お」「い」とつなげ再生すれば、非常に簡単な音声合成とも言えます。
実際には、「あ」と「え」の中間の音や、この例では使ってませんが語尾の「す」で最後の「u」の音をはっきり発音しないケース、など、単発で発音しにくいような様々な音が日本語では使われてますので、50音では済まないでしょう。また、この例では実際には「あ」と「お」の間には滑らかに中間の音が発音されるはずですが、そこをすっ飛ばして接続されると、いわゆる昔のロボットみたいなしゃべり方になってしまいます。
上の例は非常に原始的なものです。最近では処理能力の向上や、新たな手法としてディープラーニングを使ったり、音響処理の精度を向上したり、統計的な手法を活かすなど、様々な方式が登場し、より滑らかで自然な音声が使えるようになっています。このあたりはそれぞれ研究され日々発展している研究領域ですので、興味のある方は論文なども調べてみてください。
1-2 音声合成、の範囲
コンピュータを利用して以下のように音声合成を使うことを考えてみます。
①「本日の天気は晴のち曇り」、と音声にしたい
②「本日の天気は晴のち曇り」というテキストデータを準備する
③テキストデータを処理プロトコルに入力する
④「本日の天気は晴のち曇り」という音声が出力される
簡単ですが、このような行為を必要とします。この処理は、簡単な処理ブロックとしては下記のようにコンピュータ内で処理されます。
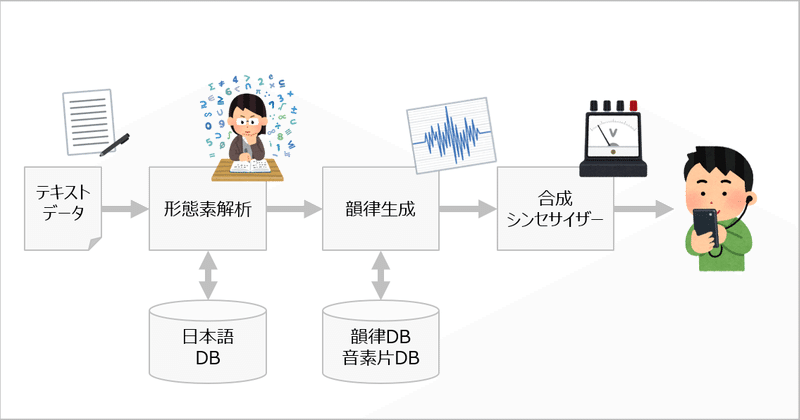
※形態素解析 日本語のルール上、該当の単語が主語なのか、述語なのか、などの品詞によって音の高低が決まります。そのため、文章を解析し品詞に分けることが必要です。日本語は主語と述語等の単語の間にスペースがありません。そのため、辞書と照らし合わせながら日本語ルールに基づき、文章を品詞に分解をすることが必要です。英語は単語と単語の間がスペースで区切られているため、比較的この処理は簡単で、そのために日本語よりも古くから音声合成が発達してきました。
※韻律生成 形態素解析により分析された日本語のルールに基づき、単語や文章の中で標準的な音程が作られます。この音程は、単語特有ではなく、使われる場所や順番によって変化をするため、一連の文章としての分析は不可欠です(焼↑きそば、のイントネーションは、ソース↑焼↓きそば、と接続した単語にすると変化します)。
※合成シンセサイザー 波形を指定し、順番に並べ、発声時の音程や長さを定め、出力します。この原理は音楽用のシンセサイザーと類似していますので、シンセサイザーでできることを音声合成に応用することも可能です。しゃべりを行う音声合成技術も、この原理を利用することで歌を歌わせるために発展させられる要素があります。
音声合成、と一口に表現されることが多いのですが、以上のように処理要素を細かく分けると下の様になるかと思います。さらに、事前に合成をする元となる音が必要になります。音素片と呼ばれる小さい波形のグループであったり、それに代わるものを計算する計算式をあらかじめ用意しておく必要があります。このコンテンツでは、主に以下の要素を解説として使います。
日本語形態素解析部
韻律生成部
合成部
+事前の音素片作成(或いは計算式)
このあとの説明でも、どの部分についての説明か、を明示しながら進めて行きます。
2 音声合成の特徴(できること、できないこと)
音声合成を実際に使う、という観点でこの文章を書いておりますので、すぐに特徴の説明に入ります。はっきりと言えば、音声合成は人間の声とは違います。ぜひ、その違いを理解し、より良い使い方に活かしてください。
この違いが出てくる理由は音声合成がまだ発展途上であるから、という理由もありますが、我々が日頃使っている日本語の文章そのものが、あいまいだったり人によって違ったりする人間側に原因がある場合も多々あります。そのため、人間側の対応を理解することで、より期待した結果を得やすくなる側面もあります。
ここから先は
¥ 990
まだまだ色々と書きたい記事もあります。金銭的なサポートをいただけたら、全額自分の活動に使います!そしたら、もっと面白い記事を書く時間が増えます!全額自分のため!