
Kindle + DeepLでデザインの名著を自動翻訳して読む

以前から気になっていたこの本、
インタラクションデザインの名著と言われていますが、長らく絶版となっていて中古価格は年々高騰する一方です。なかなか手を出しづらい値段ですが、原著の最新版である以下なら普通の価格で購入できます。
この原著を自動翻訳し日本語で読めないかと試してみました。その手順を説明します。
注意事項
今回説明する手順は、著作物の複製にあたります。著作権法では「私的使用のための複製」のみ認められており、これを超える目的での複製は著作権法に違反する可能性があります。ご注意ください。
使用環境
使用したのは以下の環境です。
Macbook Air
Automator(Mac標準搭載の自動処理ソフト)
Adobe Photoshop
Adobe Acrobat
DeepLのStarterプラン
おおまかな手順の流れ
おおまかな手順の流れは以下のような感じです。
Kindleでページ送り+スクリーンショットを自動化するAutomatorの作成
撮影されたPNG画像をPhotoshopで一括トリミング
PNG画像をPDF化。AcrobatのOCR機能でテキスト化
DeepLでPDFをまるごと翻訳
以下で詳しく説明していきます。
1. Kindleでページ送り+スクリーンショットを自動化するAutomatorの作成
はじめに、Mac版のKindleアプリで購入した書籍を表示し、スクリーンショットを1ページ毎に撮影します。自動処理にはAutomatorを使用します。
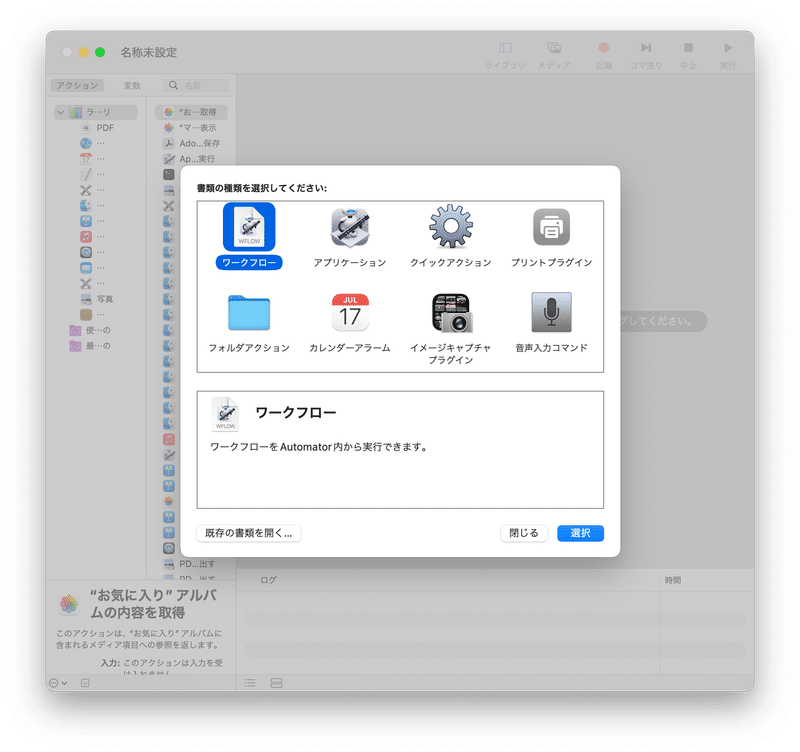
1-1. ワークフローの新規作成
Automatorを起動してワークフローを選択します。
1-2. 操作を記録
Kindleアプリで翻訳したい書籍を開きます。
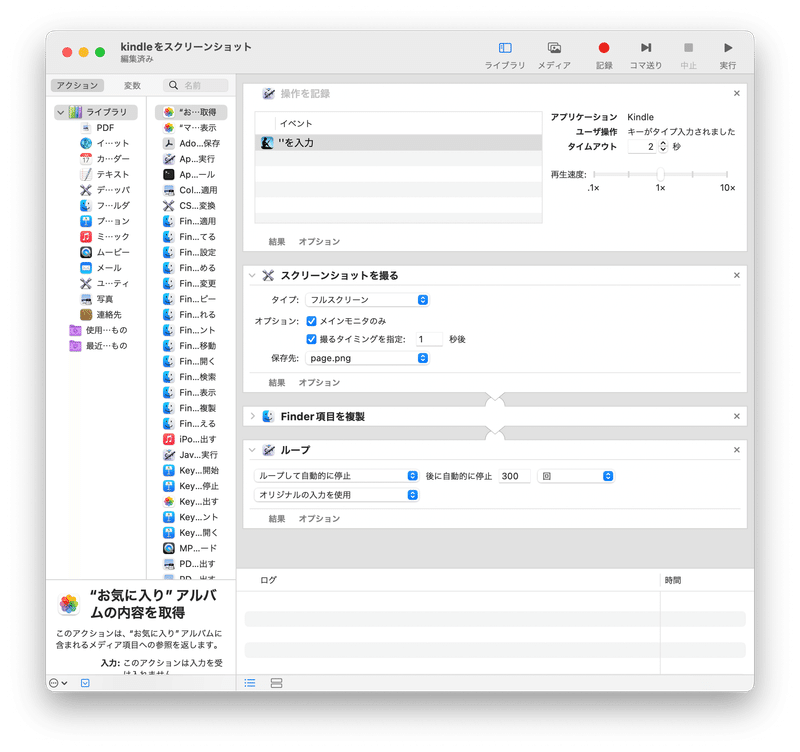
Automatorの「記録」ボタンを押し、Kindleアプリのウィンドウを選択し、矢印キーでページを送り、記録を停止します。
以下のようにKindleアプリでの操作が記録されます。
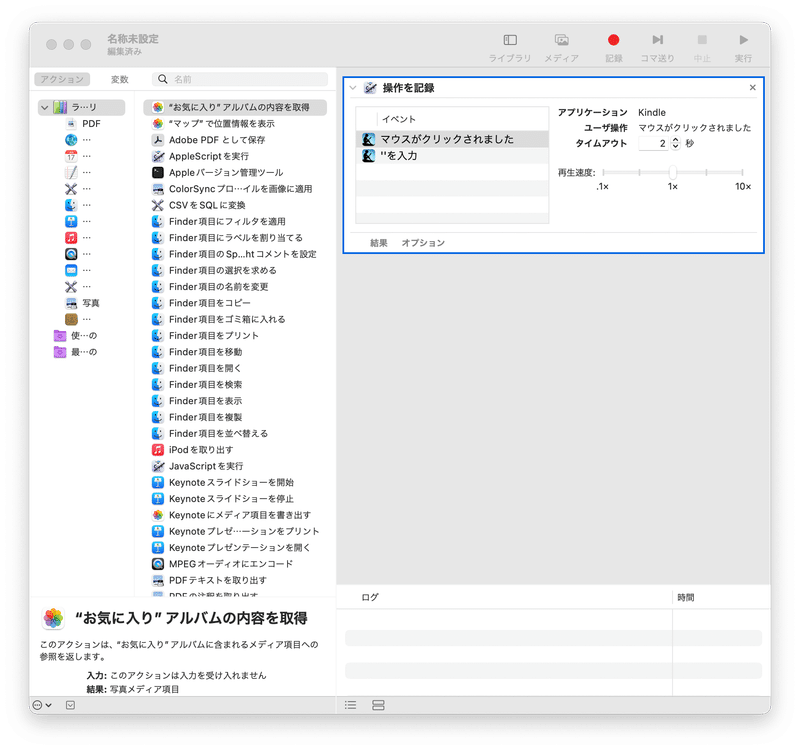
「マウスがクリックされました。」は不要なので、この項目のみdeleteキーで削除します。
1-3. スクリーンショットを撮る
「操作を記録」の下に「スクリーンショットを撮る」を追加します。
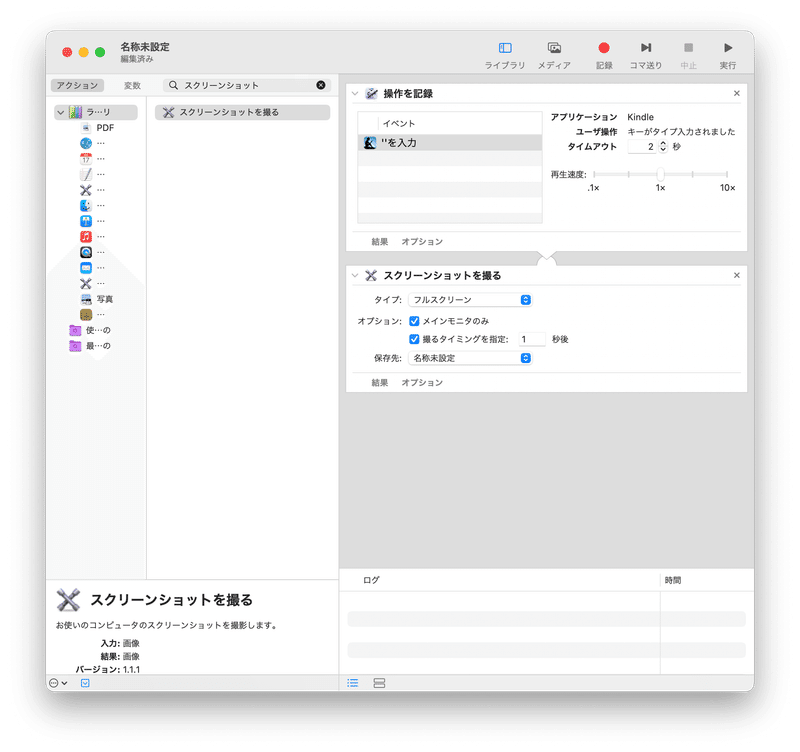
タイプに「フルスクリーン」を指定し、撮るタイミングに「1秒後」を指定します。Kindleアプリでページ送りをした際に、ページ送りのアニメーションの途中でスクリーンショットが撮影されてしまうことがあります。これを防ぐために、タイミングを1秒ずらします。
保存先は「新規」からあらかじめ作成したフォルダを指定します。
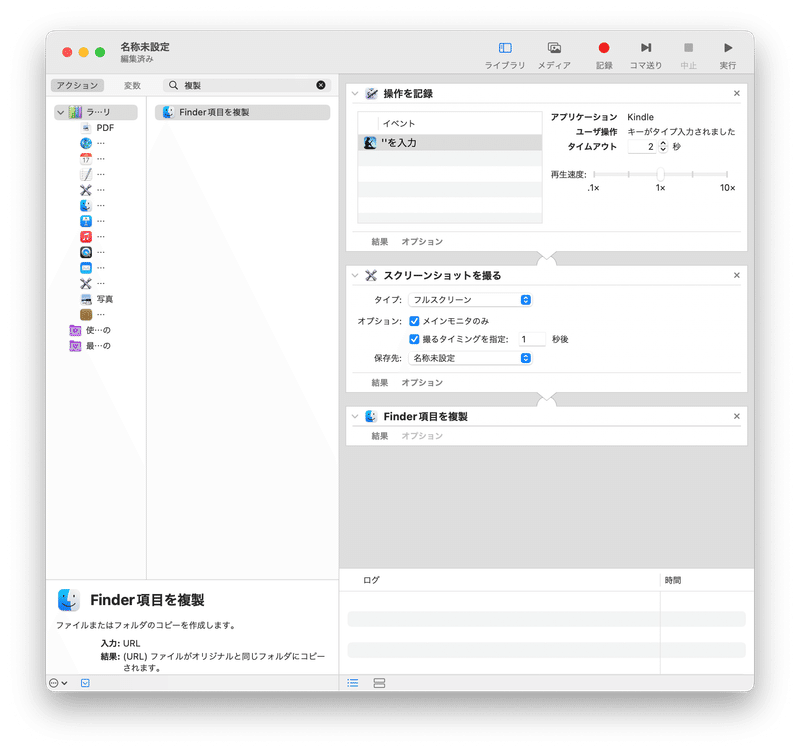
1-4. Finder項目を複製
さらに「Finder項目を複製」を追加します。これによりスクリーンショットの画像ファイル「名称未設定.png」が複製され、「名称未設定のコピー2.png、名称未設定のコピー3.png」のように連番で画像が保存されます。
1-5. ループ
ここまでの処理をページ数分の繰り返すため、最後に「ループ」を追加します。はじめは10回くらい繰り返し、問題がないことを確認した後にページ数分の繰り返し回数を指定します。
1-6. Automatorの実行
作成したAutomatorを保存し「実行」ボタンから実行します。1ページあたり2秒程度かかります。今回の書籍は900ページほどあったため、30分ほどで撮影が完了します。
撮影が完了すると、こんな感じのスクリーンショット画像がページ数分作成されます。
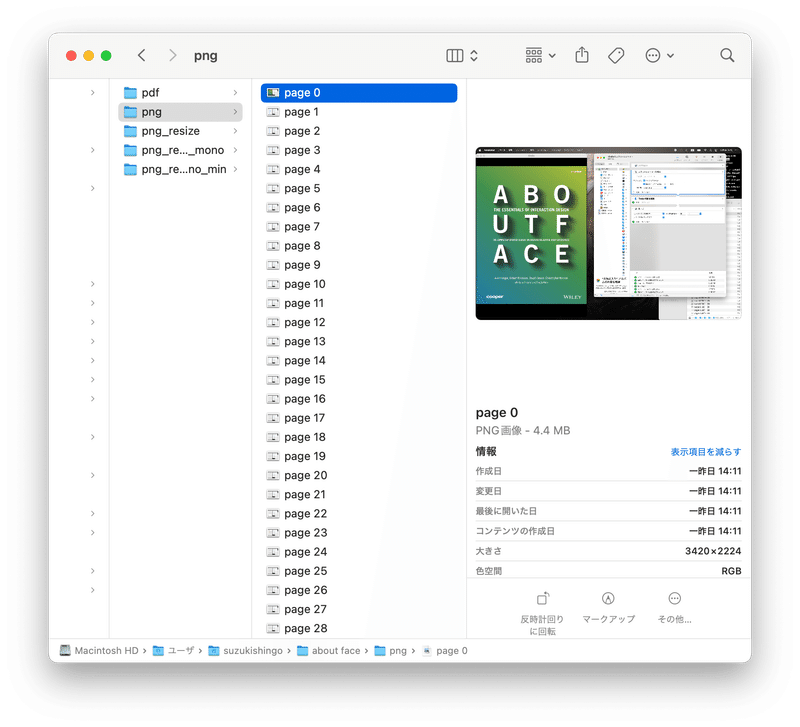
2. 撮影されたPNG画像をPhotoshopで一括トリミング
次に、スクリーンショットの画像を書籍部分のみになるように編集します。一括処理にはPhotoshopのバッチ処理を使用します。
2-1. アクションの作成
Photoshopを起動し、スクリーンショットの1枚目を開きます。メニューのウィンドウ>アクション からアクションパネルを開きます。

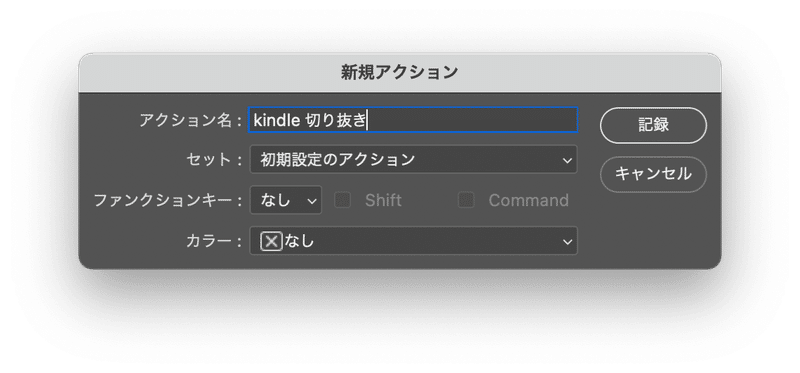
「+」アイコンから新規アクションを作成して記録を開始します。アクション名には任意の名前を設定します。
切り抜きツールを使用し、スクリーンショット内の書籍部分のみにトリミングします。
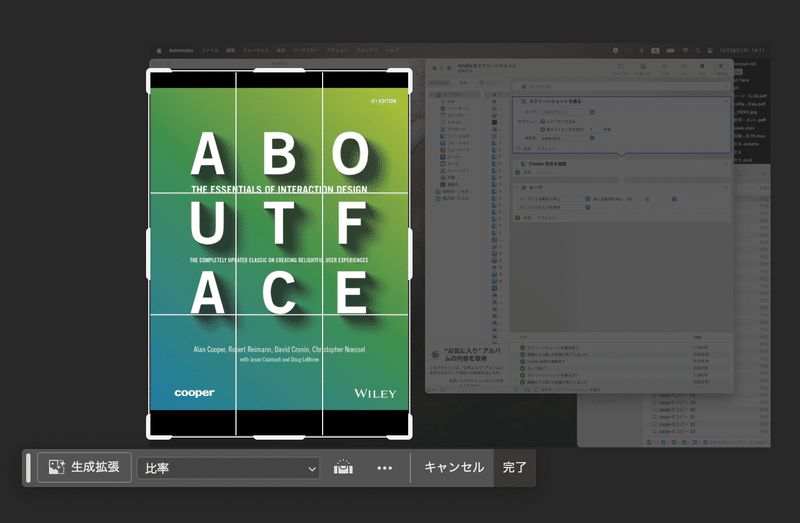
トリミングできたらアクションの記録を「■」ボタンから停止します。
以下のようにアクションに「切り抜き」が記録されます。

アクションが記録できたら、このファイルは保存せずに閉じます。
2-2. 自動処理
次に先ほど作成したアクションをすべてのファイルに対して実行します。Photoshopのメニューから ファイル>自動処理>バッチ を選択します。

以下のように設定します。
アクション:さきほど作成した切り抜きのアクションを指定
ソース:スクリーンショットの画像が格納されているフォルダを指定
実行後:「保存して閉じる」を指定
「OK」ボタンを押すと、自動処理が開始されます。
完了すると、トリミングされた以下のような画像ができあがります。

3. PNG画像をPDF化。AcrobatのOCR機能でテキスト化
3-1. PDFファイルの作成
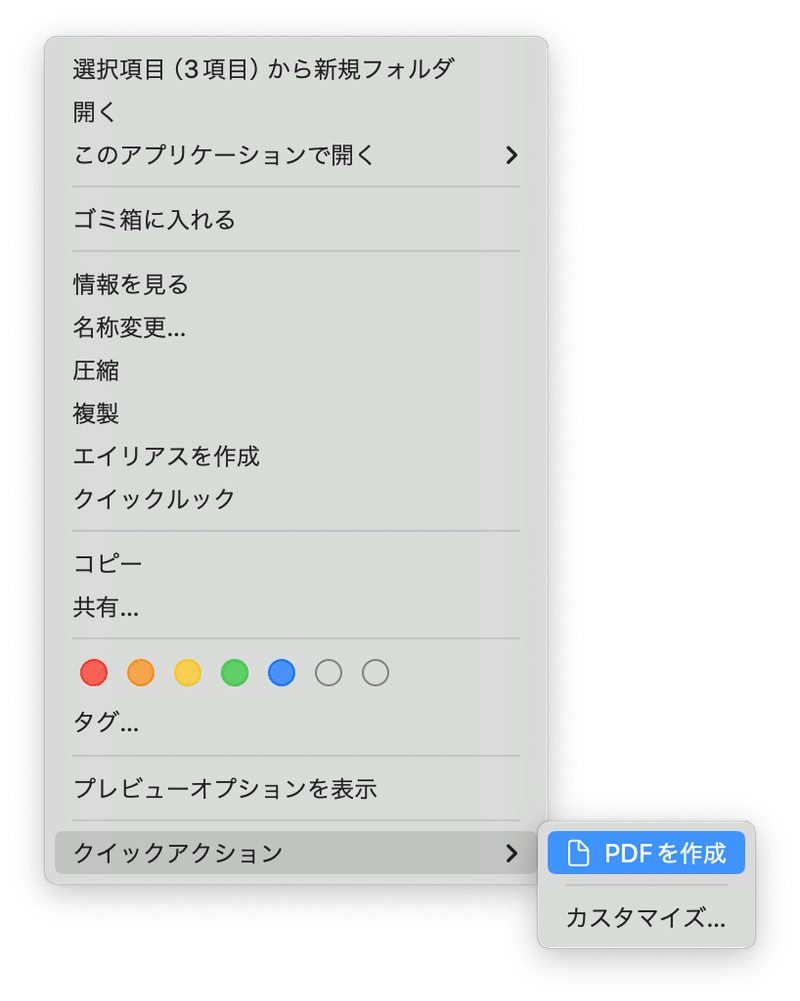
作成された画像を1つのPDFに変換します。Finderですべての画像を選択し、右クリックのクイックアクションから「PDFを作成」を実行します。
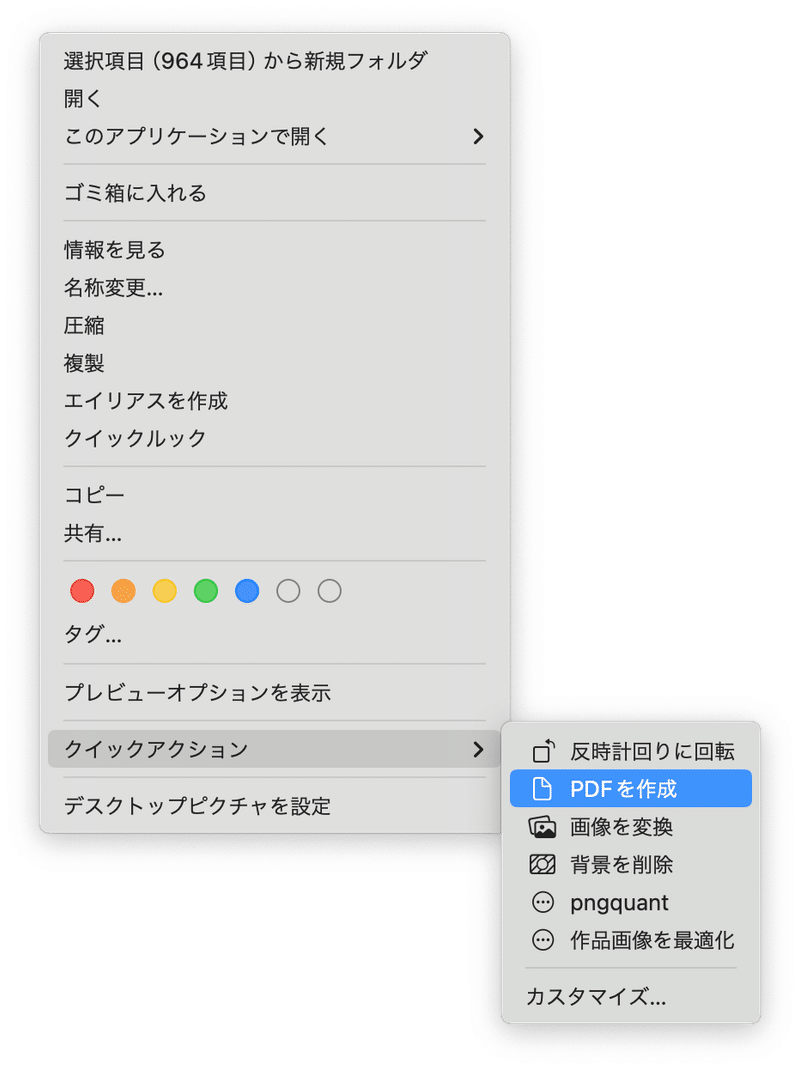
PDFファイルが作成されます。
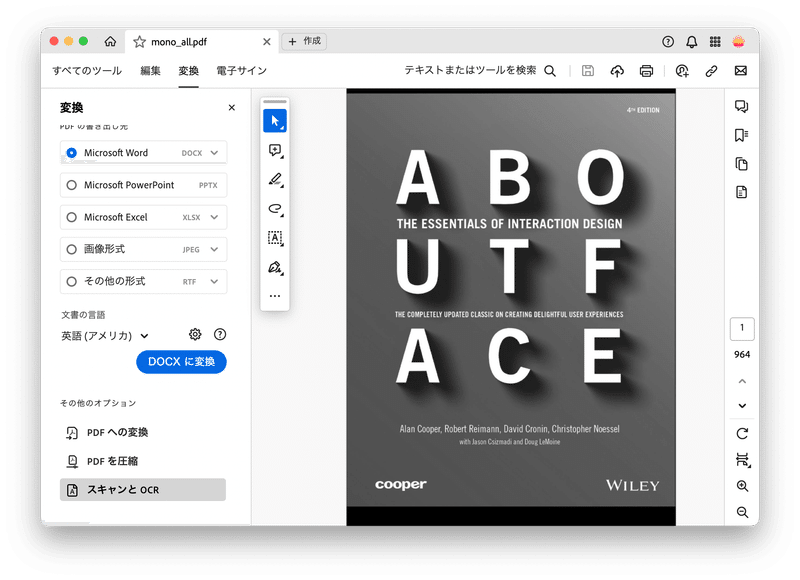
3-2. AcrobatのOCR機能でテキスト化
PDFファイルをAdobe Acrobatで開きます。メニューから「変換」を選び、「スキャンとOCR」を選択します。
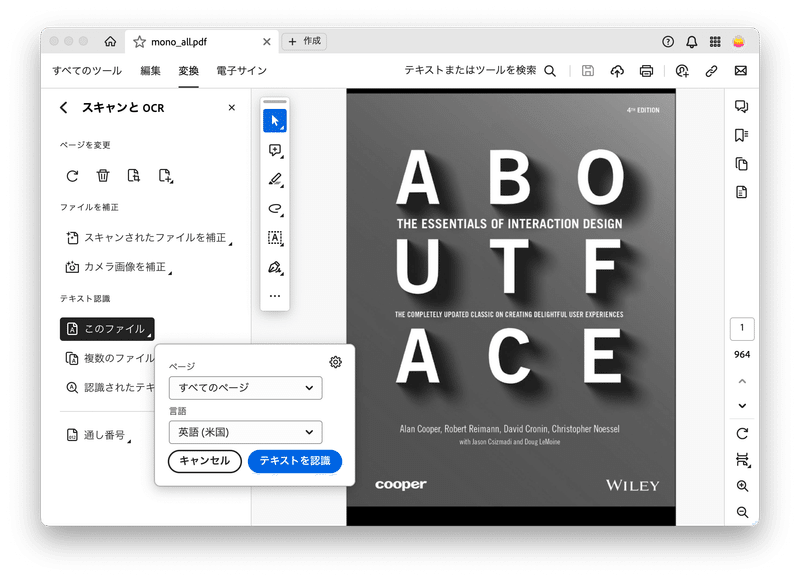
次に「このファイル」「すべてのページ」「英語(米国)」を選択し、「テキストを認識」ボタンから実行します。
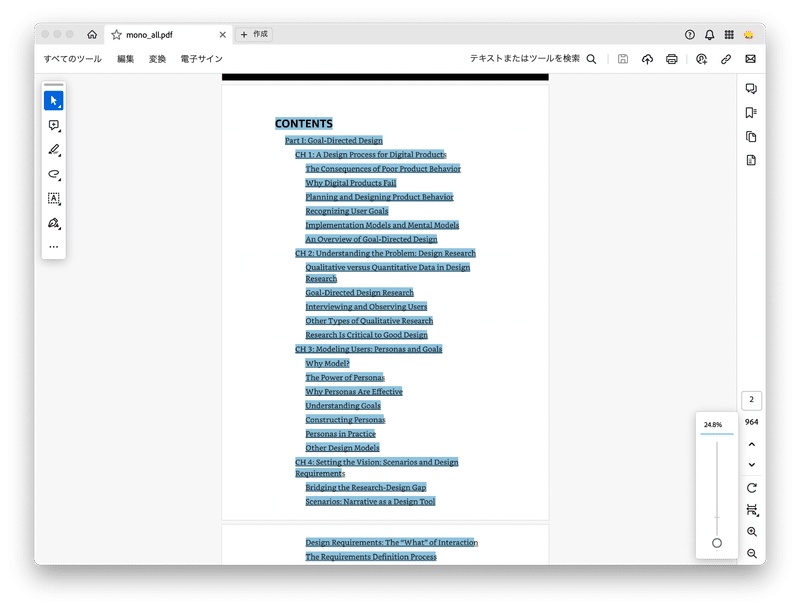
すべてのページの処理が完了すると、以下のようにテキスト選択可能なPDFファイルができあがりました。
3-3. PDFファイルの圧縮
作成したPDFファイルは460MB近くあります。次工程のDeepLでの翻訳をスムーズに進めるために、PDFファイルを圧縮してファイル容量を小さくします。Acrobatのメニューから ファイル>その他の形式で保存>最適化されたPDF を選択し、画像を可能なかぎり圧縮します。

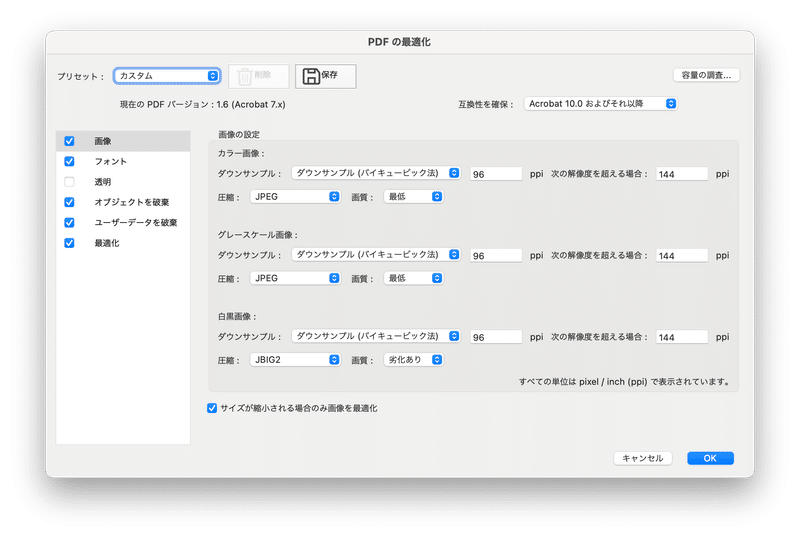
圧縮の結果、100MB程度までPDFファイルの容量が小さくなりました。
4. DeepLでPDFをまるごと翻訳
最後にDeepLを使用してPDFを日本語に翻訳します。今回はこのためにDeepLの有料プランStarterプランに登録しました。月額1,000円 × 12ヶ月ですが、30日無料で利用できます。

DeepLでは、PDFやWordなどのドキュメントファイルをまるごと翻訳してくれる機能があります。Starterプランの場合、月に5ファイル、1ファイルあたり10MBまで翻訳可能です。
4-1. PDFファイルの分割
さきほど作成したPDFファイルは100MB以上あるため、1ファイル10MB以下になるように複数のPDFファイルに分割します。
PDFファイルの分割はAdobeが公式に提供している以下のサイトから可能です。Adobe IDでログインして利用します。
1ファイルあたり10MBに収まるようなページ数でPDFファイルを複数に分割します。今回は12ファイルに分割しました。

4-2. PDFファイルの翻訳
最後にPDFファイルを翻訳します。分割した10MB未満のPDFファイルをDeepLの文章翻訳にドラッグします。
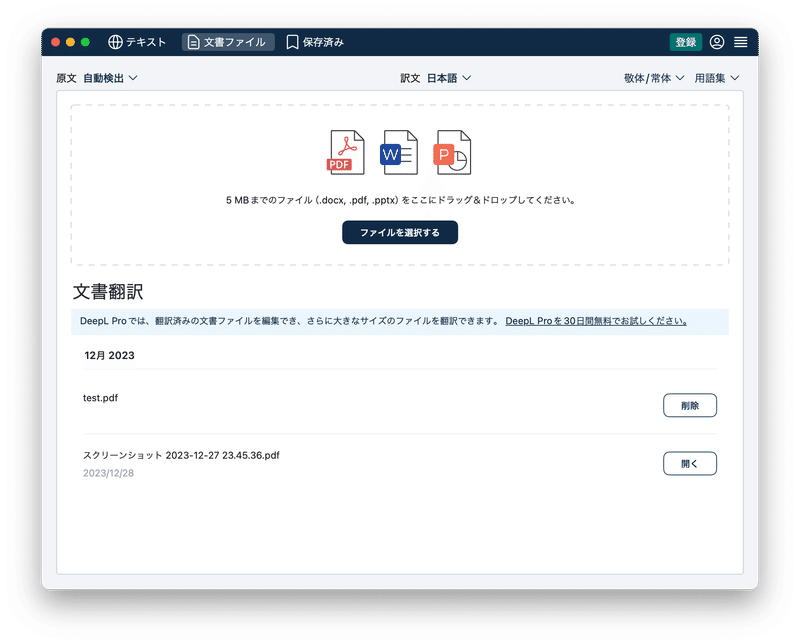
今回は、月の上限ファイル数となる5ファイルのみ翻訳し、残りは後日翻訳
することにします。
4-3. PDFファイルの再統合
翻訳後の5つのPDFファイルを選択し、右クリックから「クイックアクション>PDFを作成」で1つのPDFファイルに統合できます。
このPDFファイルをSend to KindleからKindleのライブラリに登録します。
感想
翻訳後のPDFファイルでは文字サイズが妙に大きかったり、図版部分が崩れたりなど、読みづらい部分があり、長時間読むにはストレスを感じる部分が多いです。

それでも日本語で入手しずらい書籍を手軽に読めるので、満足度は高いです。
TwitterでUIデザインについて発信しています。
感想やコメントなどいただけると嬉しいです!
この記事が気に入ったらサポートをしてみませんか?