
【シリーズ】エンジニア採用の基本の基本 -データサイエンティスト採用、AIエンジニア採用入門-

GWに結構頑張ったので、シリーズ初日初稿なのですが3本目のnote。データサイエンティストとかAIエンジニアとか、データを扱う職種についても採用の基本についてnoteに書いておきます。
初稿は以下からです。エンジニア市場全体をまとめています。
メイン画像は使いたいだけですね、すいません。マッドサイエンティスト感が変に気に入ってしまい。。
さて、エンジニア採用の中でも自分自身が最も長く携わってきたデータサイエンス関連職種について、市場を整理した上で、基本的な採用のヒントになるものを記載していければと思います。
データサイエンティスト?AIエンジニア?データアナリスト?MLエンジニア?データ解析関連職種はとにかく分かりにくい
データサイエンティストが最もセクシーな職業だと言われてから随分年月が経過し、徐々に企業にデータサイエンスが入り込んできましたが、
Webスタートアップではデータサイエンスに取り組んでいるところ、取り組んでいないところ、まだまだ差が大きく、おそらく人事の方も採用に苦労されているところもあるのではないかと思っています。
この分野で人事の方が悩まれるところは、採用頻度が少なく、あまり触れる機会がないということもあり、
・AIエンジニアとかデータサイエンティストとかデータアナリストとか色々呼び方があるけど、住み分けがよく分からない
・住み分けや社内での役割を知りたいのに、データサイエンスに関する用語がよく分からないので社内のエンジニアの人から話聞いてもよく分からないし、経歴を読んでも判断つかない、よく分からない(専門用語がいっぱい出すぎて関連性とかよく分からない)
・どういう経歴の人たちなら、何が出来て、そういう人たちがどこにいそうなのか、検討がつかない
といったところかなと思っています。
ということで今回は、例によって誰に何を伝えるのか?
※・誰に?:ペルソナとして細かく設定する
・何を?:ペルソナの悩みを解決し、かつ自社の強みが合わさる点を訴求する(つまり採用ブランディング)
という基本的なフレームの順序に沿いつつも、「誰に?」というところがやはりなかなか分かりくいところだと思いますので、
・データサイエンティストとかAIエンジニアといった呼称をフックにデータに関わる人たちの類型を整理
・AIエンジニアのペルソナを落とし込み
・最後に基本的な事項として、彼らが欲しがるのもはどんなものなのか
この辺りを整理できればと思います。
ではいきます。
そもそもデータサイエンティストやAIエンジニア的な方々の市場を俯瞰してみる
エンジニアの中でもかなりニッチだと思われるデータ解析系統職種のエンジニアですが、実際市場にどれくらいいるものでしょうか?IT人材白書2017を見てみると、IT提供側で約8,000人在籍、ITを利用するユーザー側企業で約5,000人在籍、合計でわずか約13,000人の市場です。総務省が出している転職率は平均的には約5%なので、おおよそ650人くらいが年間で動いていることになります。(但し、スキルレベル不明)
以下でIT提供側企業在籍者、ユーザー企業在籍者各々の数字を見ていきます。
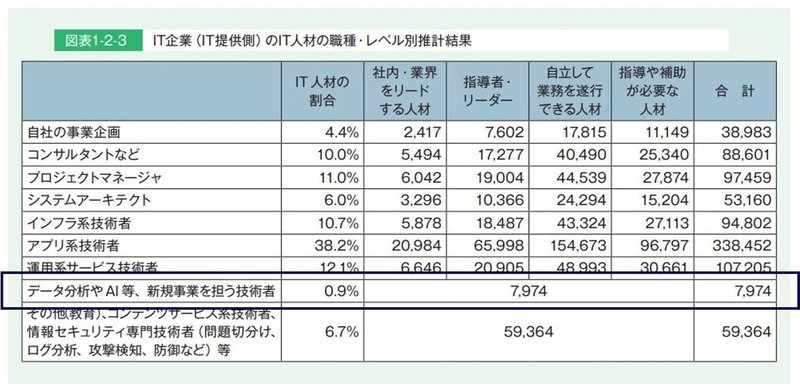
出所: 独立行政法人情報処理機構「IT人材白書2017」
上図がIT提供側のデータ解析関連技術者の人数になりますが、全体の1%にも満たない約8,000人の在籍者となっています。同IT人材白書内では、IT提供企業全体で3万社とのことなので、おおよそ4社に1社、1名在籍しているようなイメージですね。
ただ、実際の在籍は、大手に偏っていると思われ、以下のリンクは有料記事なので数字などは引用しませんが、いくつかの大手ががっつり雇用していて、それ以外の会社にはほとんどいない、ということがよく分かります。(興味がある方はリンク先の図を見てみてください)
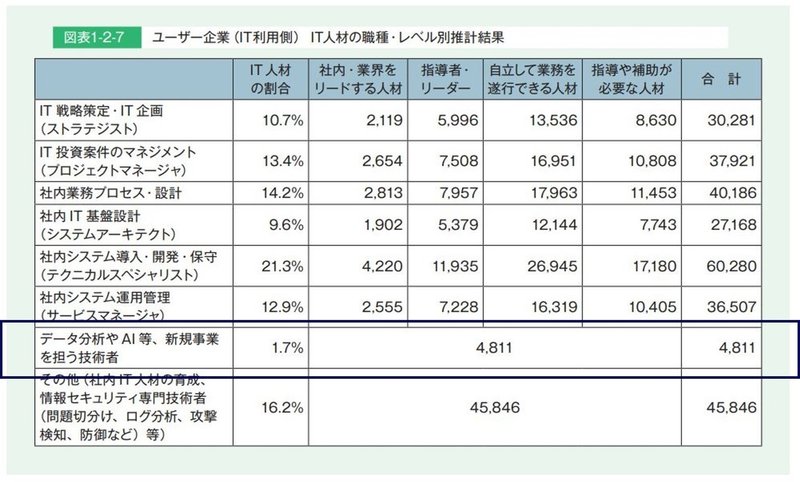
出所: 独立行政法人情報処理機構「IT人材白書2017」
上図がユーザー企業側での分析人材の在籍人数になりますが、在籍数約5,000人程度となります。これを多いと見るかどうかというところですが、提供側で8,000人しか抱えていない解析人材を事業側がかなり積極的に抱えに行っているということが見える値だなと僕は感じました。ただ、後述しますが、事業会社はAIブームが来る前からデータサイエンスを古くから導入していた業界も複数あったりするので、そのあたりも含めての人数なのかなーというところです。
データサイエンティストやAIエンジニアとは誰なのか?自社が募集する対象者はどういう役割の人で、何を期待するのか、その人はどこにいるのか?を整理する
呼称を基準に、データ分析職種を考える
ざっくりと市場の整理をしてきましたが、以降ではターゲットの整理をしていきたいと思います。
自社が募集する人を何と呼べばいいのか(求人タイトルに何の職種と書くのが正解か?)、またそれを規定する上で、自社が期待する役割が何か(どこまでのことをその人に期待するのか人事と現場で調整する)、その人たちはどこにいるのか?を簡単に整理してみたいと思います。
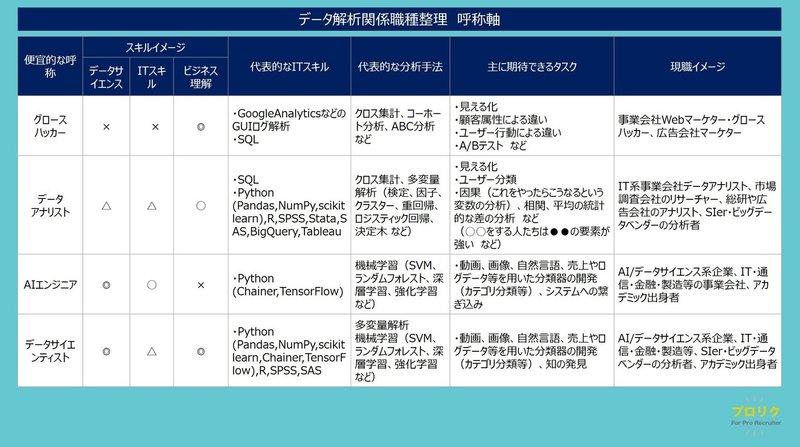
マーケティング絡みでデータを扱うエンジニアを議論されることがあるので、グロースハッカーも一応入れています。
(グロースハッカーと一時呼ばれてましたが、今はあまり使われない用語になりましたね。。)
グロースハッカーのスキルイメージ、分析手法、期待できるタスク、現職のイメージ
マーケ寄りの人、データアナリティクスの技術やIT技術に、高い専門性がある訳ではなく、基本的には深いビジネス理解、マーケターとしてのスキルに支えられ、多くはアクセスログデータ・コンバージョン率・コンバージョン値といったところを元にした、PDCAによるサービスグロースを行う人たちのことをグループピングしています。
データーアナリストのスキルイメージ、分析手法、期待できるタスク、現職のイメージ
ビジネス理解、マーケティング理解が一定ありながら、SQLや人によってはPythonも扱える人もおり、データの可視化や、多変量解析(機械学習ではない)という統計的なデータ解析手法を用いて、物事の因果を導出して、ビジネスの意味を見出していくタイプの人たちのことをグルーピングしています。
一昔前で言う、「ビッグデータをデータマイニングしてビジネスとして意味あるものを導出する」ということを期待できる層ですね。
SQLでDBからデータを抽出するとともに、Python(Pandas,NumPy,scikitlearn),R,SPSS,Stata,SAS,BigQuery,Tableauといった、言語や分析ツールのスキルを保有しています。
現職としては、IT系事業会社でデータアナリストとして活躍されている方、市場調査会社のリサーチャー、総研系の企業や大手総合広告代理店のアナリストも類似のスキルを持った方がいるかなと思います。
あとはSIerやビッグデータベンダーの分析者としてツールありきでありながら導入コンサルとして入っていって分析の知見を保有されている方々、また、製造・製薬・通信の事業会社でビジネス理解の差は一定あるかもしれませんが、分析手法として、一定の統計解析の経験を積まれている方もおられますので、ニーズによってはターゲットになりえるかもしれません。
AIエンジニアのスキルイメージ、分析手法、期待できるタスク、現職のイメージ
次に、AIエンジニアですね、もしかしたらこの記事を見ていただいている人事の方の多くの方がここで悩まれているのかなと思いますが、特にアルゴリズムを用いて課題を解決することに高い専門性を有している方々をここにグルーピングしています。
もしかしたら人事の方もTensorFlowと言う言葉は聞いたことがあるかもしれません。
TensorFlowやChainerのような非常に便利なライブラリ(すごく雑に言うとエクセルの関数のようなもの)が出てきたため、この分野に多くのエンジニアの参入が進みました(数式の中身が分からなくてもライブラリを実行すれば勝手にぐるぐる機械学習が回る環境が出来た)。
そういったライブラリを用いつつ、時には数式を実装しながら学習器を作っていくスキルを保有している方々です。
流行りのディープラーニング、強化学習、深層強化学習やGANといった様々なアルゴリズムが出ていますが、昔から存在するSVM、決定木、ランダムフォレスト、遺伝的アルゴリズムといった手法も課題に合わせて、またアルゴリズムごとの比較のために採用し、精度を高めていく業務を得意とします。
またその教師データを得るために、スクレピング・クロールの技術やデータクレンジングの技術に秀でている方も一定数おられます(分析手法名は、経歴書読み解きや、求人サービスでの検索キーワードとして利用できるかなと思います)。
動画・画像、自然言語、売上やログデータ、顧客属性データ等様々なデータを用いて学習器を開発し、データを投入すると適切な値を返す(猫の画像を投入すると猫というラベルを返す)、という機械学習エンジンを開発し、
それをシステムに組み込み、プロダクトや業務改善に生かす、ということが期待できます。
例えば、レコメンドエンジン、ファンドの自動金融売買、自動運転の物体認識、レントゲン画像の識別、監視カメラなどでの人物認識・挙動認識、
LINEりんなのような自動テキスト応答、EC商品やニュース記事のカテゴリ分類、IoTデータを用いた故障予兆、広告配信会社のログデータを生かした顧客クラスタリングなど、様々な学習器の開発が想定されます。
現職としては、AI/データサイエンス系の企業、IT・通信・金融・製造等の事業会社、また、社内に分析部署が確立されている会社では、実務経験を持たないアカデミック出身者も積極的に採用がされています。
データサイエンティストのスキルイメージ、分析手法、期待できるタスク、現職のイメージ
最後にデータサイエンティストです。
ビッグデータという言葉が流行り、次に流行ったのがデータサイエンティストという言葉だったかもしれません。
Python(Pandas,NumPy,scikitlearn,Chainer,TensorFlow),R,SPSS,SASといった言語や分析ツールを用いて、多変量解析や機械学習(SVM、ランダムフォレスト、深層学習、強化学習 など)を行い、ビジネス的な意味を見出したり、学習器を作ったりします。
AIエンジニアとの違いは、ビジネス的な示唆出しをするかシステムに組み込む実装寄りか、という点でここでは分けており、データサイエンティストはビジネス的な示唆出しをする方が多いと言うグルーピングをここではしています。(実際は同じような業務をされている方も多数おられると思いますが)
動画、画像、自然言語、売上やログデータ等を用いて学習器を開発し、
それを実データに当てはめてマーケティング施策(クロスセルアップセルのクラスタ予測や定期サービスの解約者予測など)に生かしたり、人事施策として選考基準作成や退職者予測に生かしたりします。
現職ではAIエンジニアの現職で挙げたところと非常に近いところが挙げられます。
経歴書上で、「API、実装、組み込み、自動化」といったキーワードよりも、「提言、提案、施策に落とし込み」といったキーワードがあれば、よりビジネス寄り、データサイエンティスト寄りの方だと見分けられるのではないかと思います。
データを基準にした分類でデータ分析職種を考える
世の中には様々なデータがあり、データサイエンティストやAIエンジニアの方々も扱ったことがあるデータ、扱ったことがないデータが各々あります。
そこに専門性が発生するとともに、どういうデータでどんな料理をするのか、個人のキャリアの志向性も反映されてきます。
その意味で、自分たちが持ってるデータが何で、その場合市場にどんな人がいるのか?欲しいのか?をよく考えるべきかもしれません。
単に必須要件で、「機械学習の経験者」という形でそれ以外に具体的な業務のヒントになるような記載がない求人募集している会社は、データアナリティクスの知見がない(関心が薄い)ということを露呈しているとも言えるかもしれません。
データの種類に個人のキャリアの志向性(経歴)が現われるということは、そこに触れられていない求人は、データの種類を気にする層には刺さりにくくなるということになります。
簡単に以下にデータを基準にターゲットについて表でまとめてみました。

データについて簡単に書き出すと、
・質的データ:男性(1)/女性(2)や買った(1)買わない(2)といった分類で利用するデータ など
・量的データ:古くはECデータ、広告データ、金融データ、新しくはIoTデータ など
・画像:ディープラーニングの始まりと言ってもいいくらいの領域、生物の写真(猫を猫とラベル付けできる)、人物画像(年齢や性別を当てる)、自動運転では道路や標識 ・ECでは商品画像などの物の画像、名刺画像、レントゲン画像、製造物の良品/不良品画像 など
・自然言語:Web上のテキストデータ(サイトデータ、ニュース、Twitterなど)、Q&Aデータセット(チャットボット)、履歴書・経歴書、マーケティングリサーチのアンケートデータ など
・音声:古くは波形の解析、電話、商談、会議の音声データ など
こういったデータがある中で、データごとに扱うデータの詳細や利用されている領域、経歴のイメージを書いてみました。
一般的な数量および質的データを扱われてきたエンジニア層
言い方的にあまりすっきりしないのですが、多くのエンジニアの方々がここに含まれると思います。ビッグデータ時代(データマイニングが叫ばれていた2013年頃)の初期を走った方々は、特にここに含まれる層だと思います。
経歴については詳細後述しますので割愛しますが、売り上げ数量、単価データ、商品カテゴリデータ、顧客属性、アクセスログデータなどを扱い、ECサイト、ソーシャルゲーム、Web広告、金融、通信、製造、製薬といった会社で実施されてきたとともに、業務領域としても、マーケティング・営業・人事の解析などに用いられてきています。
自然言語を扱われてきたエンジニア層
次に、自然言語を扱う方々ですね。チャットボット、マーケティングの解析などで主に用いられていますが、自然言語解析は古くから研究が進んでいる分野のため、昔からのアカデミック出身者も一定数いる領域になります。
一方で、IBM Wantsonを中心としたチャットボット市場の勃興で研究やプロダクトが盛り上がり経験する人が増えましたが、実質多くのチャットボットはAI化されていないことが多いので、AIができる人と思って採用すると全くAIには関わっていなかった、というケースもありえますので、その意味でレベルの差は激しいかもしれません。画像による機械学習は多くの方が触れられているということから、あえて自然言語のスキルを伸ばしたいと考えて、
キャリア選択するような方もいたりします。
画像データを扱われてきたエンジニア層
画像、動画(静止画)を扱う方々としては、製造(自動運転、品物検知)、ECサイトなどITサービス、医療、建設、など多くの領域に広がりを見せており、AIベンダーはもちろんのこと、事業会社でも画像を用いた学習器を作られた方も増え続けているように思います。
一方で、ディープラーニングと言えば画像という認知が多かった為、画像からデータサイエンスに入る方が多く、初心者の方を含めて携わっている方が多い領域であり、自然言語と同様レベル差は激しいかもしれません。
実用性という点では画像による学習器は対応領域が広く実社会への実装事例が多いため、市場の需要を見極めて画像分類の道を極めようとする方もいます。
その他データを扱われてきたエンジニア層
次にその他データとして、例えば音声データ、IoTなどの時系列データをあげてグルーピングをしてみました。音声系は電話、IoT(製造、不動産、建設)は今広がりを見せています。
音声の波形を分析することは昔から行われておりアカデミック出身の方も一定数市場にいると思われます。IoTデータ解析は少しずつ経験者が増えている状況だと思われます。IoTデータの解析で言うと、機械の故障予測がよく言われる主な用途ですが、これからは産業向けだけではなく住まいなどの個人向けにもより広がりを見せる(経験した方があまりいない)と思われるので、その場合は経験者を求めるよりも、時系列データの解析の要点を理解している方を採用していく、という形になるかと思います。
また、今は音声→テキスト化、画像→テキスト化、テキスト→画像生成、といったように、データを横断して学習器を作り実装するような業務も増えているので、今後はデータ横断の経験者も増えていくものと思われます。
AIエンジニア採用のターゲットを深掘る
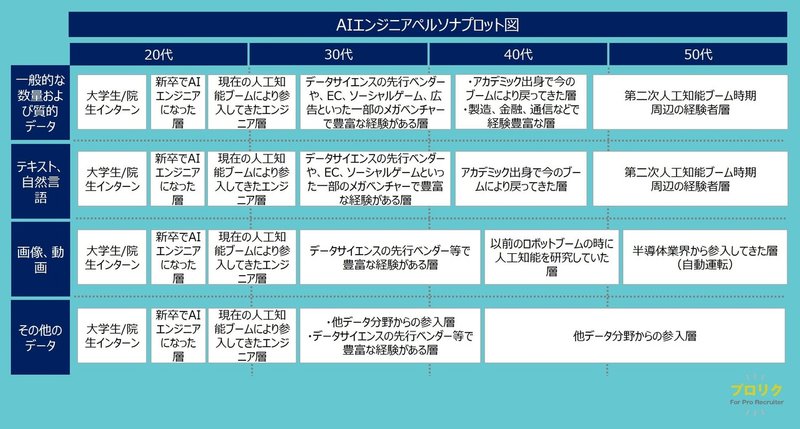
これまでは色々なデータを扱う色んな人がいますよ、ということで整理してきましたが、もう少し解像度を上げて、データ分類と年代に分けて、代表的な経歴イメージをプロットしてみました。セグメントとしてかなり細かく分けれるということが見て取れると思います。
昨今のブームを見て参入してきた方々をはじめとして、第二次人工知能ブーム時期に関わられてきた方々、今のブームを見てデータサイエンス分野に戻ってきた方々など、多様な方々がデータサイエンスの分野で活躍されています。
一般的なデータを扱ってきたAIエンジニアの方をもう少し深掘る
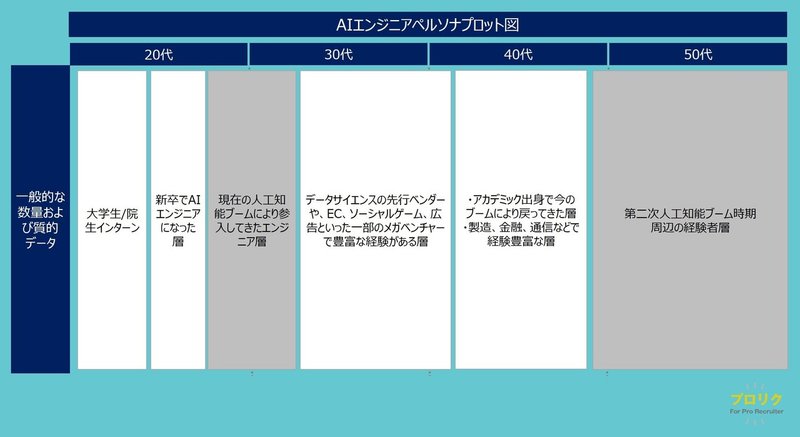
以降では更にターゲットを細かくしていきます。
今回は一般的なデータを扱ってきたエンジニアの層をターゲットとして仮定しより細かくしていきたいと思いますが、Webスタートアップの人事が、AIエンジニア採用を考える上で、「現在の人工知能ブームにより参入してきたエンジニア層」、「第二次人工知能ブーム時期周辺の経験者層」は一旦外して考えてみようと思います。
理由は、「現在の人工知能ブームにより参入してきたエンジニア層」は、機械学習の経験は決して豊富ではないのですが、プログラミングの経験は一定程度ある方が多く、その場合、システム開発者としての水準の給与を前提として転職活動をされることが多く(この逼迫した環境ということもあり)、ご自身として経験少ない機械学習エンジニアという職種において前職と同水準の給与となると、スキルの割に給与が高いという状況が発生してしまいがちのため、需要と供給がマッチしにくいからです。
「第二次人工知能ブーム時期周辺の経験者層」は、スキルは十分な方が多いですが、カルチャーマッチ的なところが難しいかもしれないという懸念があるからです。
Webスタートアップにおいては、機械学習においてもアジャイルかつクイックに取り組む会社が多いと思われますが、この層は専門性が高くじっくり研究に取り組まれて来た方が多かったりするので、クイックに回すことに慣れていなかったり、曖昧なまま進めていくといった面においてマッチしにくいかもしれないためです。
ということで、「一般的な数量および質的データ」に絞ってより詳細に記載したものが以下です。
AIエンジニア(一般的な数量および質的データ)ペルソナ詳細
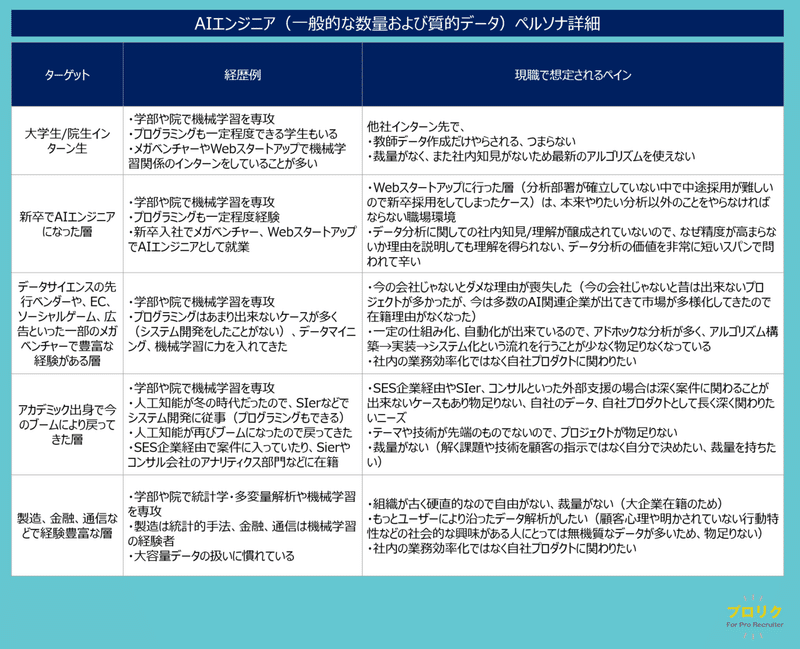
ターゲット別に、経歴イメージとそこで想定されるペイン(キャリア上の悩み)を整理しています。
ちなみに、念のために書いておくと、(1)これは正解を言うゲームではなく、また正解を1人の人間が言える性質のものでもない、(2)だからこそ仮説として検証されうる対象である、という性質のものかと思っています。僕自身はAIエンジニアではないですが、仮にAIエンジニアの方が考えた場合でもその方のバイアスがかかったサンプル1の意見となり、他の方の意見だと割れる可能性も十分あるわけで。そもそも市場の意識構造を適切に捉えることは非常に困難(だからこそマーケターは、マーケティングリサーチというものをして、一定のサンプル数のデータを元にデータ解析をし、生活者の意識構造をできる限りモデル化して明らかにしようとするのだけれど)である、という理解の元で読んでいただければ嬉しいなと思うとともに、アイデアある方と建設的なディスカッションをして僕自身も深めていきたい点でもあります。
ということで、以下各々説明していきます。
大学生/院生インターン生AIエンジニア層の経歴や現職で想定されるペイン
大学生/院生インターン生も状況によっては選択肢として検討しても良いかもしれません。
学部や院で機械学習を専攻し、プログラミングも一定程度独学や長期インターンで経験している人もいて、データクレンジングや機械学習モデルの、サービスや業務システムへの組み込みまで期待できるケースがあります(実際に著名なAIスタートアップ、ITスタートアップのある種サービスのコアになっているアルゴリズムを、インターン生が作っていたという話はよく聞いた話です)。
彼らのインターン先は、メガベンチャーやWebスタートアップで機械学習関係のインターンをしていることが多いように思いますが、そこでの悩みが、機械学習業務に触れると思ったものの雑用的に教師データ作成だけやらされる・つまらないといった状況に陥ってしまうケースや、アルゴリズム(分析の方法論)に触れるものの、社内にデータアナリティクスの知見がないために基礎的な分析に止まってしまって最新の機械学習アルゴリズムは利用できなかったり、裁量なく自分でアルゴリズムごとの比較検討も出来なかったり、といったペインが想定されます。
新卒でAIエンジニアになった層の経歴や現職で想定されるペイン
新卒でAIエンジニアになった層はもしかしたら良いターゲットになるかもしれません。
アカデミックの素地があり、かつプログラミングも一定程度長期インターンなどで経験しており、新卒入社でメガベンチャー、WebスタートアップでAIエンジニアとして就業している方々で、20代後半くらいの層です。給与水準も高過ぎず、経験も一定程度あり、学習器の開発からシステムへの組み込みまで難易度が高いものでなければスムーズかもしれません。
この層のキャリア上のペインを考えてみると、特にWebスタートアップで新卒入社した場合、その会社の状況にかなり左右されますが、ここでは分析部署がまだ確立していない中で、中途採用が難しいので新卒採用をしてしまったケースを想定します。そのような場合、そもそも分析によって達成したいこと、が不明瞭であるケースが多くあり(分析そのものを目的化している)、本来やりたい分析業務になかなか取り組めず、そもそも分析でできることの説明、期待値調整といった社内向けの工数が大きくかかるとともに、
データ分析環境やデータを綺麗にする作業(データクレンジング)、分析後の社内説明ドキュメント作成など、やりたかったことをすぐに出来ない状況にまず当たっているはずです。
さらに、データ分析に関しての社内知見/理解が醸成されていないと、なぜ精度が高まらないか理由を説明しても理解を得られない、データ分析の価値を非常に短いスパンで問われる、といったデータサイエンスの市場が未成熟であるが故の問題点が色々出てきます。こういった悩みに対して、どう訴求するかが募集企業には問われています。
データサイエンスの先行ベンダーや、EC、ソーシャルゲーム、広告といった一部のメガベンチャーでAIエンジニアとしての豊富な経験がある層の経歴や現職で想定されるペイン
次に本格的な経験を保有するターゲットである、データサイエンスの先行ベンダーや、EC、ソーシャルゲーム、広告といった一部のメガベンチャーで豊富な経験がある層です。
アカデミックな背景を元に、実務として2000年代後半、2010年代前半くらいからデータ活用の取り組みをしていた方々のグループとしています。データ分析コンサルティング会社のような外部支援という形で関わっているケースもあれば、ゲームや広告といった分野で自社の分析に関わっているようなケースもあります。
ただ、こういった方々はプログラミングはあまり出来ないケースを多く目にし、システム開発そのものはしたことがなく、データマイニング、機械学習に特化して言語を書いていた、というケースが多いかなと思います。
したがって、システム実装寄りのニーズがある場合は、社内に繋ぎこみをする方がいてという体制が望ましいのかもしれません。
こういった方々のキャリア上の悩みは、大きな不満はないものの、例えば今の会社じゃないとダメな理由を喪失しているケース、今の会社じゃないと昔は出来ないプロジェクトが多かったけれど、今は多数のAI関連企業が出てきて市場が多様化してきたので在籍理由がなくなったというようなケースや、
他社に先行してデータサイエンスのプロジェクトを進めてきていることもあり、一定の仕組み化、自動化が出来ているのため、大きなプロジェクトが一旦収束し単発のデータ分析案件が今は社内では多く発生している。従って一定程度時間をかけて行う、「アルゴリズム構築→実装→システム化」という流れを行うことが少なくなり、物足りなくなっている、といったケースが想定されます。
また、社内外の業務効率化だけでは手触り感が少なく物足りなくなり、自社プロダクトに関わりたいといったところも想定されます。
アカデミック出身で今のAIブームにより戻ってきたAIエンジニア層の経歴や現職で想定されるペイン
次に、アカデミック出身で今のブームにより戻ってきた層ですが、
アカデミックの素地があるものの、社会に出るタイミングでは人工知能はブームが過ぎており冬の時代であったため、SIerなどでシステム開発に従事、昨今の人工知能ブームにより昔の知見と開発スキルを生かして、再び人工知能領域に戻ってきた、という方々です。少し年齢的には上の方が多いです。
現在は、SES企業経由でデータサイエンスの案件に入っていたり、SIerやコンサル会社のアナリティクス部門などに在籍されているケースを多々見かけます。
こういった方々の悩みは、SES企業経由やSIer、コンサルといった外部支援の場合は深く案件に関わることが出来ないケースもあり物足りないといったところで、自社のデータ、自社プロダクトとして長く深く関わりたいニーズがあります。また、テーマや技術が先端のものでなく(以前行ったテーマと同じ業務を繰り返し)、プロジェクトが物足りない裁量がない(解く課題や技術を顧客の指示ではなく自分で決めたい、裁量を持ちたい)といった悩みが想定されます。
製造、金融、通信などでAIエンジニアとして経験豊富な層の経歴や現職で想定されるペイン
最後に、製造、金融、通信などで経験豊富な層が挙げられます。学部や院で統計学・多変量解析や機械学習を専攻され、現職で製造は統計的手法、金融、通信は機械学習の経験者となります。
この層の悩みは、組織が大企業であるため、古く硬直的で自由がない、裁量がないといったところや、もっとユーザーにより沿ったデータ解析がしたい(顧客心理や明かされていない行動特性などの社会的な興味がある人にとっては無機質なデータが多いため、物足りない)、社内外の業務効率化だけでは手触り感が少なく物足りなくなり、自社プロダクトに関わりたいといったところが想定されます。
AIエンジニアには何を訴求したら良いのか
これまでAIエンジニアを例にデータ関連職種のターゲット設定について整理を進めてきましたが、ではこういった方々に対して何を伝えれば良いのか?という点が次のフェーズです。
実採用業務上は、これまでに示してきたペルソナに沿った訴求を考えていく必要がありますが、今回は「AIエンジニア採用、データサイエンティスト採用入門」ということで、すごく簡単にデータを扱う方々がどういうところを気にしているのか、記載したいと思います。
1,データサイエンスを生かして解決する課題は何か?を明確にし、書き出しておく
何の課題を解決したくてデータを解析するのか、という点です。ここが明確でないプロジェクトに取りかかることをAIエンジニアは回避されるように思います。
AI・機械学習は魔法だと思っている会社があって苦労した的な話は、データサイエンスに関わるエンジニアの方々各所で記事を書かれていますが、一定の解像度で自社の課題が求人に記載されておらず、作業としてデータ解析が依頼されるようなイメージの求人の場合、課題設定なくとりあえずデータ分析したら何か出る、と思っているのでは?とエンジニア側から疑問を持たれてしまう恐れがあると思われます。簡単に言うと、分析職種的な意味でのブラック企業認定がされてしまい、避けられてしまうと言う話になるかと思います。分析に対する理解が希薄で、丸投げにされそうで、でも機械学習に関する期待は大きいのでその期待値コントロールからしなければならない、心的負担が大きいそう、みたいなところが透けて見える会社はやっぱり避けられてしまう、という話ですね。
従って、少なくともこの点は募集開始前に、人事が現場に掛け合って明確にしておきたいところです。もしこれが明確にならないのであれば、いきなりAIエンジニアの正社員募集をかけるのではなく、外部のAIフリーコンサルを雇って、自社の課題の紐解きから、保有しているデータは何で、何が出来そうか議論に入ってもらってから正社員募集を考えても遅くはないかと思います。(往々にして、なんとなく描いている「機械学習でやりたいこと」は機械学習を使わなくても出来る、むしろ使わない方が良い、といったケースに陥りがちということもありますし。。)
2,扱うデータを書き出す
何のデータがどれくらいの量あるのか、を書き出すということです。
そもそも学習させるデータ(量および質)が社内外に無い場合は取り組めないというのは容易に分かる点かもしれません。前述の点と同じように、そもそも社内にどんなデータがどれくらいあるのか明確に書き出せないくらいの分析ブラック企業はちょっと厳しいな、となるかなと思います。
データを扱うエンジニアとしては、今ライバルとなるエンジニアがどんどんデータサイエンスの市場に参入してきているので、自らの領域を極めようという動きになってきている面もあり、データの種類によっては取り組みたい/取り組みたくないといった意向が変わるケースもあったりします。
データを分析するのだからなんでも良いということではなく、取り組めるデータは何かを求人やスカウト上で示しておくことでプラスに働くと思われます。
3,相対するテーマを書き出す
より実務的な話になりますが、何をテーマとして業務に取り掛かるのか?という点です。
解決する課題に密接にひもづきますが、
課題:売上減少(を食い止めたい)→テーマ:顧客の解約を予測する
みたいな繋がりを指しています。
テーマが決まると機械学習のタスクに落とし込みやすくなるので、テーマまで掲示できるとかなり具体的なイメージを持って、エンジニアの方々にも求人を見てもらえると思います。ただ、社内の戦略を外部に示すことにもなり得るので出し方には注意が必要がところかもしれません。
4,機械学習のタスクを書き出す
機械学習を用いて、何をタスクとするのかということですが、
課題:売上減少(を食い止めたい)→テーマ:顧客の解約を予測する→タスク:解約をしやすい顧客クラスタの予測モデルの構築
みたいな繋がりを指しています。
まだ分析に全く取り組まれていない場合はなかなか難しいかもしれませんし、ここまで記載してしまうと相当程度機密情報に触れてくるところにもなるかと思いますが、技術的チャレンジとして採用広報的な意味でオープンにしても良いといったケースの場合は、是非オープンにすることでエンジニアの方にとって業務がかなり明確になるため、より具体的なイメージを持った求人として見てもらえるのではないかと思われます。
-------------------------------------------------------
以上、簡単ですが、データ解析職種について整理し、訴求についてまとめてみました。参考になりましたら幸いです。
最後に、AIエンジニア採用支援ならプロリクへ
弊社はAIエンジニア採用に強みを持って、採用ブランディング、採用代行のご支援しています。
是非ご要望あればお声がけいただけますと幸いです。
この記事が気に入ったらサポートをしてみませんか?