記事一覧


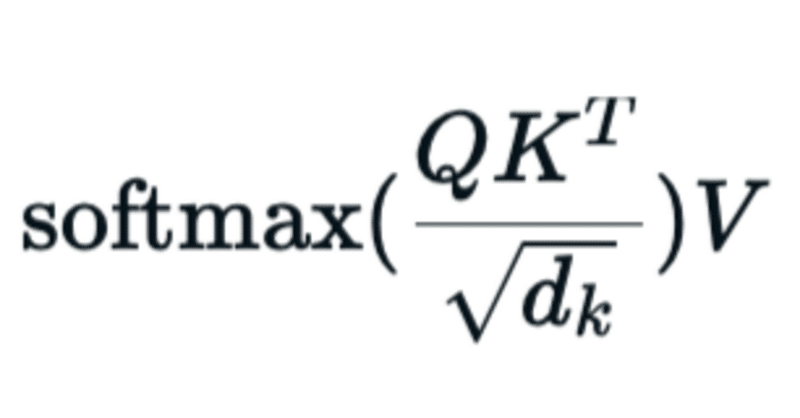
何故AttentionのSoftmaxはEmbeddingの次元数の平方根で割らなければならないのか?
$$
\text{Attention}(Q, K, V) = \text{softmax}(\dfrac{QK^T}{\sqrt{d_k}})V
$$
Why $${QK^T}$$ should be divided by $${\sqrt{d_k}}$$?
こう考えたことはないだろうか?その答えの全てはAttention is all you need.の論文に書かれている。
Scaled
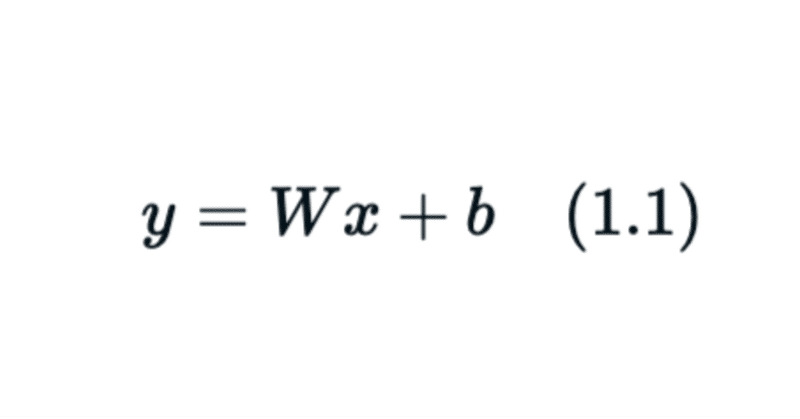
小話: 機械学習系の論文実装で気をつけて読むべきほぼ唯一の箇所, 行列演算
この記事は3分程度で読み終わる小話になっています。
この記事の対象者
・何でもかんでもフルスクラッチで一度は論文実装しなければ気が済まない人
Qiitaにも投げようかと思いましたが, Qiitaは実装の話をする場なのでNoteに投稿しました。
と言っておきながら, 実は過去にQiitaに数学の話を投稿してしまっています。いいねとブクマお願いします。
本題まずは簡単な線形層を考えていきましょう
東大本郷キャンパス付近以外の最寄駅のラーメン屋について
EEICアドベントカレンダー3日目です。
2日目にこんな記事が投稿されました。
なるほど、ならばEEICに入ってからインターンで稼いだ給料を"""全て"""ラーメンに溶かしている僕は本郷周辺のラーメン屋を紹介しなきゃいけません。(義務感)(エンゲル係数1000%)鈴春これは12/2の担当者が紹介し忘れていたので紹介します。
後楽園のラーメンも紹介しておきます。
はぐれ雲次は丸の内線に乗って淡