
「ビッグデータ」って、なんで注目されてるの?

『誰もが嘘をついている ビッグデータ分析が暴く人間のヤバい本性』という本を読みました。
ぼくは大学で社会心理学を専攻してまして、いまは来年の卒論でなにを書こうかなあと、思いをめぐらせているところです。
実験方法もどうしようかな〜と考えていたところ、TwitterでフォローしているGo Andoさんがちょうど本書をおすすめされていたので、その場でポチりました。
本中では、ビッグデータを用いた社会学分野の可能性ついて書かれた本なんですが、序文からなんとも心理学あるあるすぎるネタがぶっ込まれていて、一気に引き込まれました。
標本数が小さすぎることがもたらす実験結果の偶然やいたずらや歪みを一般化して、それが米国人の特質、ひいては人類全般の特質であると推論してしまうのだ。それらは単に便宜的に標本を集めたとき―特に学部二年生を薄謝で釣って被験者に募ったりしたとき―に起きる気まぐれに過ぎないのに。
後半にある「特に学部二年生を薄謝で釣って被験者に募ったりしたとき」というのがなんともあるあるなネタで、教授はもちろん、卒論を書く学部生なんかは特にこれをやりがちです。
別に学部二年生自体に罪はないんですが、なにが問題なのかというと、「ヤル気」がないことです。
理由は「真面目に実験に取り組むインセンティブがない」からです。
なけなしの謝礼は「実験に参加すること」に対するインセンティブであって、「真面目に答えること」のインセンティブではありません。
このインセンティブ構造の問題は、学部二年生だけではありません。
クラウドワークスなどでアンケートを実施した場合も、すごく適当に答えられていて、「人間の本性」からは程遠い回答が返ってきます。
というわけで、「人間の本性」を得る手段として、実験室やアンケートの限界がそれなりに露呈しつつあるいま、「ビッグデータ」が新しいソースとして期待されています。
特に本書の冒頭にも出てくる「グーグルトレンド」は、上述した「インセンティブ構造の問題」を、きれいサッパリ解決してくれるものとして、ぼくは読みながらものすごく胸が躍りました。
ビッグデータだけの括りでいえば、「グーグルトレンド」も「SNS投稿」も同じ部類に入るんですが、「インセンティブ構造」の観点からいくと、SNS投稿すらも欠点を抱えています。
というのは、SNS投稿は「見栄を張りたい」という、永遠に枯渇することのない人間の欲望によって下支えされているからです。
そのため、ビッグデータのひとつとして期待されいてるSNS投稿でさえも、「盛り表現」や「嘘」が入り乱れていて、「人間の本性」からは遠ざかってしまう面もあるのです。
その点、「グーグルトレンド」には「自分はこういうことが知りたい!」「こういうことに興味がある!」以外の邪心が入り込みづらい、まさに「人間の本性」にとても近いソースになり得ます。
こういう理由で、ぼくは本書を通じて一番「グーグルトレンド」に希望を見出したんですが、このあと紹介する「面白かった研究事例」はそれだけに限らず、ビッグデータ全般からピックアップしていきます。
ビッグデータの、なにがそんなにいいの?
ここまでのだいぶ長い前置きでは、どちらかといえばグーグルトレンドに焦点を当てて書いてきましたが、本全体を通じては、タイトルの通り「ビッグデータ」の可能性について説かれています。
最近よく聞くようになり、バズワード化している側面もあるビッグデータという単語ですが、、、とすんなりいってもいいのですが、せっかくなので、グーグルトレンドで「ビッグデータ」と検索してみましょう。
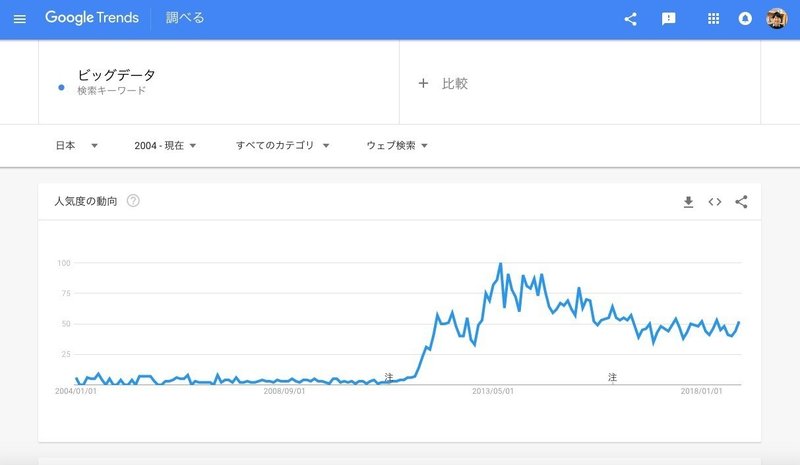
期間は2004年1月~現在(2018年11月)です。グラフを見ると、2011年7月頃から急激に上昇し始め、2013年7月にピークを迎えます。
その後は緩やかな下降線に入り、2016年7月頃からは微増微減を繰り返してるという感じですね。
ですので、お世辞にもホットワードとは言いづらいですが、まあ15年前に比べたら圧倒的に検索数は増えてるので、「最近よく聞く」と形容しても問題ないでしょう。
ちなみに本書のなかで、著者はあえて「ビッグデータ」の厳格な定義をしていません。「なぜなら本質的に曖昧な概念だからだ」と言っています。
なので、本noteでも「めっちゃ多いひとまとまりのデータセット」くらいのゆるい感じで扱います。
というか、このnoteを読んでくれている方のなかには、「そもそも、そんな大量のデータを集めてこなくても、人間の傾向なんて直感的になんとなくわかじゃないですか」と思っている方もいるかもしれません。
その通りです。
人間の直感は、まあまあ正しいので、それによって観察された人間の本性も、当たっていることがよくあります。
ただ、たまに外します。
なぜならば、人間の判断には「バイアス」がかかっていたり、「ヒューリスティック」が使われていたりするからです。
自分の経験した出来事はたまたま起きた偶然かもしれなのに、それを過度に一般化したり、数自体は多くないのに、その出来事の印象が強いために、数を多く見積もってしまうことがあります。
(ここらへんの詳しい話は、『ファスト&スロー』という本に書かれています)
そこで客観的な情報から人間の本性を暴き出そうとするのが、「実験・調査データ」というわけです。
ただ、既存のデータ収集方法では、圧倒的に「数」が足りません。
冒頭の引用部分前半を、もう一度掲載します。
標本数が小さすぎることがもたらす実験結果の偶然やいたずらや歪みを一般化して、それが米国人の特質、ひいては人類全般の特質であると推論してしまうのだ。
これは「少数の法則」とも言われ、要はサンプル数が圧倒的に少ないのに、そのなかで出た結果を過度に普遍化してしまう問題のことです。
これでは、人間の直感をあまりバカにはできないですね。
そこでようやく登場するのが、「ビッグデータ」というわけです。
こんなことを言ってはすべてが終わってしまいますが、人間の本性なんて、そんな簡単にわかりません。
たいていの事象は、調べれば調べるほど「まあそれはケースバイケースだよね」という結論に帰結します。
だから、既存の少ないデータでは、できる限り様々なケースを想定「しない」ようにして、大雑把な結論を導いてきました。
ただでさえ少ないデータの数をケースごとに分類してしまったら、それこそ「少数の法則」街道ど真ん中を突っ走ってしまう羽目になります。
しかし、ビッグデータなら、その事象をケースごとに分類して、より柔軟で現実に即した結果を出すことができます。なぜならビッグなデータだからです。
.....と、現在の社会学・心理学研究に対する問題意識をぶちまけていたら、思ったより字数が多くなってしまいました。。
面白かった事例のピックアップは、明日やります。
★最後にもう一回、ぼくの問題意識を叫んどく
最後まで読んでいただいて、ありがとうございます!!!すこしでも面白いなと思っていただければ「スキ」を押していただけると、よりうれしいです・・・!