【スライド解説】知識ゼロからAIブームを理解する②

社内勉強会でのスライド資料をベースに書いた記事です。
前回の記事はこちらから。
今回は、今の「AIブーム」が起こるまでの道のりと、
その中核にある機械学習や深層学習の概要について解説する。
第3次AIブーム
なんとなく感じている人がほとんどだとは思うが、
数年前から、世界中で空前の「AIブーム」が巻き起こっている。
実は、人工知能がブームになったのは今回が初めてではない。
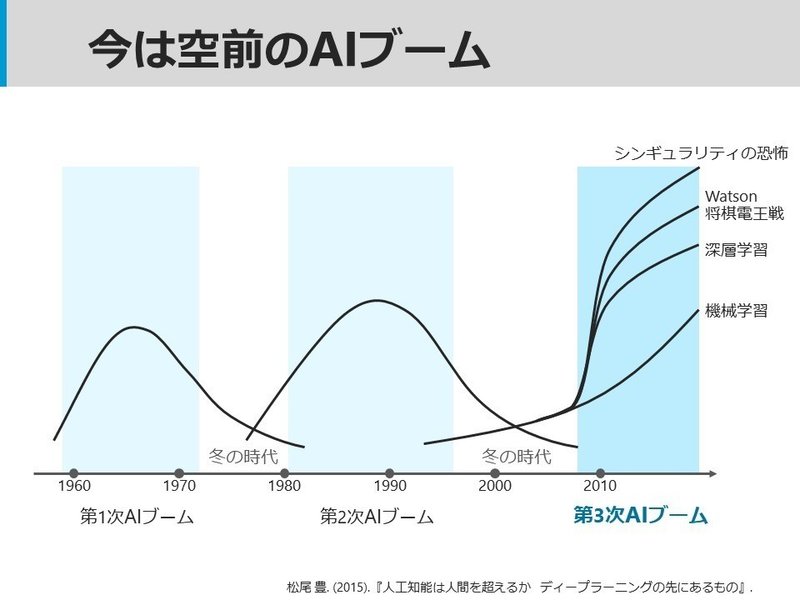
詳しい説明は割愛するが、
AIという概念が誕生したり、機械学習の様々なアルゴリズムが生まれたりして、期待が高まりながらも、
必要なデータが足りなかったり、当時のコンピュータの性能では追い付かなかったりして、
研究などの特定の範囲での活用に留まっていたのが第1次、第2次AIブームだ。
しかし、AIという言葉が生まれてから約半世紀経ち、
様々なテクノロジーの進歩によって、一般社会へ広く実用化し始めたのが、
今の「第3次AIブーム」である。
では、なぜ今このタイミングで実用レベルに成長したのか。
これは、次の3つのテクノロジー分野の発展が上手く重なったからだと思われる。
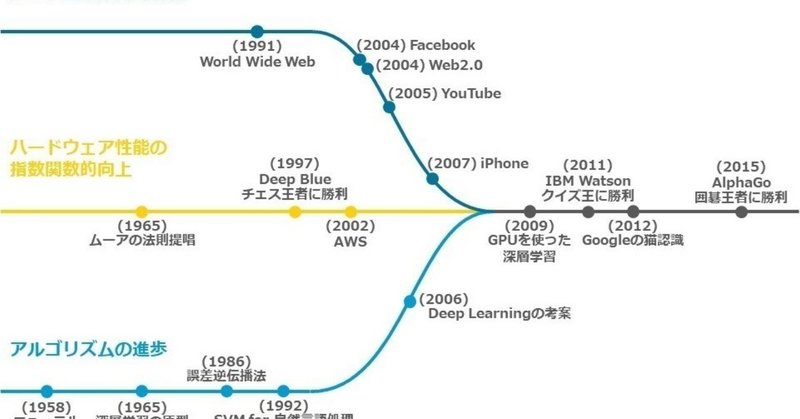
・データ量の爆発的増加
・ハードウェア性能の指数関数的向上
・アルゴリズムの進歩
マッキンゼーが分かりやすい解説を公開しているので、そちらを参考にまとめてみよう。
①クラウドやSNS等の普及により、膨大な量のデータ(いわゆるビッグデータ)が得られるようになった。
②さらに、ディープラーニング(後述)等の機械学習アルゴリズムが進歩した。
③それらの大量のデータと複雑で高度な計算を処理できるレベルまで、コンピュータのストレージ(記憶装置)とパワー(計算能力)が向上した。
ちょうどこの3つが2010年前後でがっちり噛み合って、
そこからAI技術の進化はさらに速度を増したのだ。

機械学習(Machine Learning)
さて、言葉はよく聞くけれど、よく分かっていないという方も多いのではないだろうか。

機械学習にもいろいろなアルゴリズム(計算のやり方)があって、それぞれ少しずつ異なるが、
基本的には、大量のデータから法則性を見つけてルールを作る学習のフェーズと、
そこで作ったルールに従って、入力データに対し、予測や提案、判断をする推論のフェーズに分かれる。
「AI=機械学習」というイメージも持たれがちではあるが、
実際にAIだと思って接するアプリケーションの部分は、あくまで学習を終えた推論のフェーズであって、
その場で機械学習が動いているわけではない場合がほとんどだ。
では、主な機械学習の手法を、3つ挙げよう。

教師あり学習
学習データに正解のラベルを組み合わせて学習させるやり方。
例えば、画像認識で、犬の画像には「犬」、猫の画像には「猫」という正解のラベルをセットにして大量に学習させることで、
犬の画像をインプットしたときに「犬」と答えられるようにする手法だ。
教師なし学習
正解ラベル無しのデータから学習させるやり方。
有名なのが「Googleの猫認識」で、YouTubeの動画データを中心に膨大な量の画像データを一週間、教師なし学習させることで、AIが「猫」を認識するようになったというもの。
人間が「猫」という概念を教えることなくそこに至ったということで、非常に注目された。
強化学習
試行錯誤を繰り返しながら、価値を最大化するよう行動するのが強化学習。
囲碁や将棋のようなゲームや、株やFXの取引のように、正解があるわけではない中で、少しずつより良いやり方を追求していくような場面で使われる。
ひとつの施行の良し悪しを、どう評価する仕組みにするのかが非常に重要だ。
ニューラルネットワーク(Neural Network)
Neural(神経の) Network(通信網)は、人間の脳細胞の神経回路網を、ぐっと単純化して、
数学的なモデルとしてコンピュータ上で表現したものだ。
本来の生物学的な意味で神経網との区別のため、人工ニューラルネットワーク(ANN:Artificial Neural Network)とも呼ばれる。

そして、上の図のように、人工ニューロンのレイヤー(層)を多数重ねたものを、ディープニューラルネットワーク(DNN)という。
脳の構造をそのまま再現しているわけではないが、あくまでそれを模したモデルであり、従来よりも少し人間に近い思考ができるようになった。
深層学習(Deep Learning)
で、そのDNNを用いた機械学習を、深層学習(ディープラーニング)という。
よく「機械学習とディープラーニングの違い」みたいなテーマの記事を見かけるが、
あくまで、ディープラーニングは機械学習の手法のひとつであるという認識が正しいだろう。

「ディープラーニングは凄い」とよく言われるが、従来の機械学習とは何が違うのか。
実は、多くの機械学習は、単に良いデータをたくさん集めれば正しく学習するというわけではない。
人間が指定しなければならない要素というのもいくつかあって、
それをどう設定するかによって、性能は大きく変わってしまう。
その人間が設定しなければいけない要素のひとつが「特徴量」という変数で、
その設定や組み合わせを、人間が指定せずとも自ら決定するという点が深層学習の大きな特徴だ。
特徴量というのは、その対象のデータの特徴を定める変数のことだ。
例えば小売店の売上予測であれば、
曜日や時間帯、天気、気温、あるいは駅からの距離や階数など、様々な要素が売上に影響すると思われるが、これらの要素が「特徴量」になる。
ディープラーニングでは、どの特徴量を抽出して、どれくらい考慮するのかを自ら決定するということだ。
とはいえ、もちろんディープラーニングは万能ではない。
現状、力を発揮しているのは、主に画像処理や自然言語処理の分野だ。
(※コンピュータが使うプログラミング言語に対して、人間が日常的に使う言語を「自然言語」という。)
ディープラーニングが凄いと言われているのは、
特徴量を自ら設定できるからというだけではないと思っている。
本質は、人間並みの精度で画像と自然言語を認識できるようになったというところにあって、
これによって、コンピュータは「目」と「耳」を獲得したということが重要な意味を持つ。
その結果、その他の機械学習やセンサー、ロボット技術と組み合わせることで、
より人間らしい振る舞いが可能になったのだ。
以上、機械学習や深層学習の説明を簡単にしてみたが、
実際の事例をたくさん調べてみて、その裏側がどういう仕組みなのか考えてみると、もっと理解が深まるだろう。
次回は、個人的に気になったAIの活用事例をいくつか紹介しようと思う。
飲食店の開業を目指して準備をしています。バカな若者をちょっと応援したいと思った方、サポートお願いいたします。 スキ・コメント・SNSシェアだけでもとても嬉しいです。