
【最新版対応/5万文字】 基礎で周りを追い抜く Stable Diffusion 徹底入門❗/ 『WebUI の使い方・導入方法・基本・仕組み・画面説明』など、読むだけで初心者がプロになれる❗【全体公開✨】

Stable Diffusion は最も有名な画像生成AIのうちの一つですが、最近はその最新版である Stable Diffusion XL(SDXL)がリリースされたり、Controlnet の新機能が続々登場したりと、最近の生成AIの技術は短いスパンでの進化が凄まじいです。
また、最近はかなり実用的に使用できるようになってきましたので、SNS やニュースでの情報を期に Stable Diffusion を始めた方も多いのではないでしょうか。
進化の凄まじい画像生成AI の業界ですが、だからこそ 基礎 の部分が重要になってきます。
本稿では、最近 Stable Diffusion を使い始めたという方や、今までずっと感覚的に使ってきたという方などへ向けて『Stable Diffusion という画像生成AIの仕組み から 使い方、ひいてはその実用的な応用例』についてまで、詳細に解説していきます。
この記事を最後まで読むことによって、たとえ Stable Diffusion を全く知らない状態てあっても、基礎だけで周りのユーザーを追い抜くほどの知識やスキルを身につけられるはずです。
● 前提条件 (Stable Diffusionの使用環境)
この記事は Stable Diffusion WebUI と SDXL が導入されている事を前提に進めていきます。
Stable Diffusion WebUI で SDXL を使用するには『NVDIA製のグラフィックボードでかつ VRAM 16GB 以上を搭載したPC』が必要になり、そのスペックのPCを購入するには 約30万円以上の料金がかかります。
本稿の解説でも、それと同等の使用環境があることを前提に解説を進めます。
とはいっても、Stable Diffusion の利用にいきなり約30万円の初期投資ができる人はそういないと思いますので、私の記事では
Amazon Sagemaker Studio で無料利用。
Paperspace Gradient で課金し、より高性能なGPUマシンで利用。
それでも物足りなくなったらハイスペックPCを購入する。
といった優先順位での利用を推奨しております。
そのため、そのような性能のPCを持たない方は、 私の別の記事で解説している『クラウドサービスから Stable Diffusion WebUI を使用する方法』を使用して、同等の環境で利用することができますので、まずは以下のリンクから登録・導入作業をお願いいたします。
① 【無料】 Sagemaker Studio で利用する方法
こちらの方法は、無料で行うことができ、VRAM 15GB を搭載したGPUマシンを使用することができます。つまり、最新版モデルであるSDXLを使用することができます。
具体的には、Amazon Sagemaker Studio で Stable Diffusion WebUI を使用する方法を詳細に解説しており、 煩わしい導入作業や起動もワンクリックで 行うことができます。
無料であることのデメリットとしては、ベータ版であることと、1日に4時間の使用制限があることが挙げられますが、 1日の利用制限を実質ないことにする方法も解説しています。
『 ひとまずは無料で試してみたい』『 マネタイズできてきたら有料のサービスを利用したい』といった方は、以下のリンクをクリックしてご利用ください。
② 【月額8$】 Paperspace Gradientで利用する方法
こちらの方法は、 月額8$ (約1180円) で行うことができ、VRAM 16GB を搭載した、 さらに高性能なGPUマシンを使用することができます。
具体的には、Paperspace Gradient で Stable Diffusion WebUI を使用する方法を詳細に解説しており、 こちらでも煩わしい導入作業や起動もワンクリックで行うことができます。
また、こちらの方法では 1 日の利用制限等は特になく、当然 SDXL を使用することも可能です。加えて、初月無料で利用する方法も紹介しております ので、費用を抑えることもできます。
『もっと画像生成の時間を短縮したい』『 もう一歩踏み込んでStable Diffusion WebUI を使ってみたい』といった方は、以下のリンクをクリックしてご利用ください。
⚠ 本題に移る前に、メンバーシップの説明をさせてください。
🎈 たった一晩でプロのイラストレーターになれるメンバーシップ 『あいラボ (AI-Labo)』
このブログでは、月980円で私が書いた有料記事が全て読み放題になるメンバーシップに加入することができます。
有料記事では、生成AI を使った創造的なコンテンツをお届けしています。
具体的には、以下のようなものがあります。
どんなPCでも、たとえスマホでも Stable Diffusion XL(SDXL)を無料 or 低額で使用する方法
SDXL を使用するには VRAM16GB 以上のGPUを搭載したPCが必要であり、そのスペックのものを購入しようとすると最低でも30万円はします。
これを、ある方法を利用することで無料もしくは低額で利用できますので、実質 約30万円 が丸々お得になります。
👇 詳細は以下クリック👇(マガジンにまとめてあります。)
SDXL で思い通りの画像を生成して、自分の絵をもっと好きになる方法
Stable Diffusion は最も画像生成の幅が広く大変機能の充実したジェネレーティブAI ですが、使いこなすにはコツがあります。
実は、少し工夫を加えるだけで生成画像のクオリティが格段に良くなるのですが、あまり多くの人はその方法を使っていません。
つまり、その方法を使うだけで、例え初心者であってもすぐに周りを追い越すことができます。その最短距離をお教えします。
👇 詳細は以下クリック👇(マガジンにまとめてあります。)
SNS を自動化して、Stable Diffusion を使ったSNS運用をする方法
SDXLの導入と画像生成のコツがわかったら、次はSNSなどで発信して、ポートフォリオを作り副業にしたり、社会貢献に使ったりなどなど、色々な道があると思います。
そのため、Stable Diffusion の知識に加えて、SNSを自動化する方法も案内しています。ここでは、SNSで毎日決まった時間に画像付きの投稿をする方法などもまとめておりますので、毎日のSNS運用がぐっと楽になるはずです。そうして空いた時間を、画像生成や他の活動に回すこともできます。
👇 詳細は以下クリック👇(マガジンにまとめてあります。)
このように、メンバーシップではこれらの記事が全て読み放題になり、その中には通常は3000円近い有料記事も含まれていますので、今ならそれらも980円で閲覧できる事になります。
今が最もお得な時期になりますので、是非メンバーシップに登録して生成AIの魅力を体験してみてください!
👇 以下をクリックして、すぐに登録できます👇
それでは、続きを解説していきたいと思います。
● 本稿における諸注意
▫ この記事の記載内容について
本稿では、Stable Diffusion にまつわる全てをかききると記事が膨大な量になるため、詳細を別の記事に記載してそのリンクを案内しているものもあります。その中には現在執筆中のものもありますので、予めご了承ください。
▫ 料金の表示について
本稿では各サービスの利用料金も併せて案内しておりますが、こちらはサービスの料金設定の変更や為替の変動により実際の価格とは異なる場合があります。
▫ ファイルの場所の表記 (Path) について
本稿では、ファイルやフォルダの場所を指定する際に『Path(パス)』という表現を用います。
パスとは、ファイルやフォルダを指し示す文字列です。
例として『/ui/models/Stable-diffusion』というパスの場合は、以下のように、一番上のフォルダから『ui → models → Stable-diffusion』といったように遷移した場所を指します。
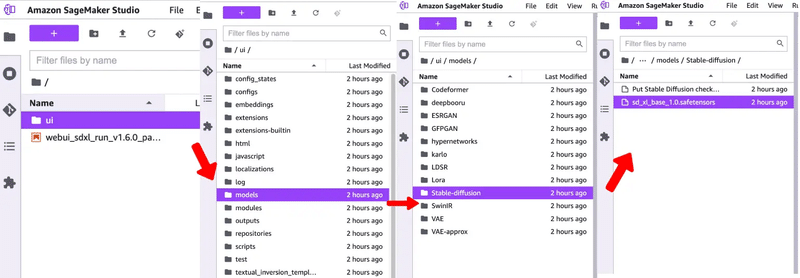
▫ 解説に用いる Stable Diffusion のバージョン について
Stable Diffusion WebUI にはいくつかのバージョンがあり、バージョンの違いによって使用できる機能や画面項目の配置が異なります。
本稿では『Stable Diffusion WebUI AUTOMATIC1111 - version: v1.6.0』というバージョンを使用して解説を行います。(以下 Stable Diffusion WebUI v1.6.0)
Stable Diffusion WebUI v1.6.0 の詳細に関しては以下をご確認ください。
● Stable Diffusionとは?
Stable Diffusionとは、2022年に公開 (オープンソース化)されたディープラーニング(深層学習)の高性能画像生成AIモデルです。
数十億の画像と言葉のペアを学習することで、『テキストの指示による画像生成・元画像を参照した画像生成』などが可能です。
画像生成AIとは、テキストや画像などの入力から、新しい画像を作り出す人工知能のことで、最近では、高品質なイラストや写真を生成できるAIが話題になっていますが、その中でも多くのユーザーに利用されているのが Stable Diffusion です。
Stable Diffusion WebUI とは?
Stable Diffusion WebUIとは、Stable DiffusionというAIモデルをブラウザで使えるようにしたインターフェースで、テキストから画像を生成したり、既存の画像にテキストで指示を与えて変更したりすることができます。
Stable Diffusion WebUIは、AUTOMATIC1111という開発者がGitHubで公開しているもので、WindowsやMacなどのローカル環境で動かすことができますが、快適に動作させるには M1以上のMacbookか、NVIDIA製GPUと8GB 以上のVRAM を搭載したPC が必要になります。
これらのPCを購入しようとすると最低でも12〜15万円ほどの費用がかかりますので、GPUを使用できるクラウドサービスを使用したほうが、コスパ良く、より性能の高いGPU を使うことができます。
クラウドサービスを使用してStable Diffusion WebUI を使用するにはちょっとした手順が必要になりますので、以下で詳細に解説しています。
▫ 無料でクラウドサービスを使用して Stable Diffusion WebUI を使用する方法
▫ 8$ (約1180円) でクラウドサービスを使用して Stable Diffusion WebUI を使用する方法
なぜ Stable Diffusion WebUI を使う必要があるのか?
Stable Diffusion WebUI には、アウトペインティング、インペインティング、カラースケッチ、プロンプトマトリックス、アップスケール などの機能もあり、さまざまなAIイラストを作成することができますが、ControlNet という強力な拡張機能もサポートしています。
加えて、2023年7月に Stable Diffusion XL(以下 SDXL)という最新版のモデルが登場し、簡単なプロンプトでも Stable Diffusion WebUI からとても高品質な画像生成ができるようになりました。
Stable Diffusion の他にも、Midjourney や Niji journey、DALL-E3 といったAI画像を生成するサービスはありますが、それでもStable Diffusion のユーザーが多いのは、絵柄を左右する学習モデルが多く、この ControlNet のような拡張機能も数多くあり生成方法の幅がとても豊富なためです。
Midjourney や Niji journey、DALL-E3 も非常に高品質な画像を生成できる便利ツールですが、どうしても『AI にほぼ任せた画像生成』になりがちなので、プロンプトで伝えきれない事はやってくれないといったデメリットがあります。
その Stable Diffusion の拡張機能の代表格でもある ControlNetとは、Stable Diffusion のAIモデルをさまざまな条件で制御できるようにするためのニューラルネットワークの構造や機能の総称になります。
先程もお伝えした通り、Stable Diffusionは、テキストから画像を生成することができるモデルですが、ControlNetを使うと、エッジやセグメンテーション、ポーズや手書きのスケッチなどの画像も入力として使えるようになります。
つまり、ControlNetは、AIイラストの生成において、空間的な一貫性や細かな制御を可能にする画期的な技術であるわけです。
ちなみに『Midjourney や Niji Journey』にもControlNetと似たような機能はあるのですが、使用できる機能の幅が圧倒的に違います。また、最新の機能も Stable Diffusion WebUI の方が利用できるようになるのが早く、アップデートの頻度も多いです。このように、ControlNet で画像の構図を指定したり画像の特徴を引き継いだりなどできるのは、Stable Diffusion WebUI ならではの強みになります。
とはいっても、『Stable Diffusion WebUI』と『Midjourney や Niji journey、DALL-E3』などの画像生成AIツールは一長一短ですので、どちらが良くてどちらが悪いといった風ではなく、DALL-E3 で 生成した画像を Stable Diffusion WebUI で加工する などのように、両者の特徴を活かしながら併用して使用するのがベターかと思います。
● Stable Diffusion XL 1.0 (SDXL) とは?
これまで、『SDXL』というという単語が何度がでてきましたが、こちらではその説明を行います。
SDXL の特徴
Stable Diffusion XL 1.0(以下 SDXL) は 7月27日に Stability AIが発表した最新画像生成AIモデルです。
従来の Stable Diffusion の進化版で、BaseモデルとRefiner モデルという2段階のアーキテクチャを採用することにより、高品質で奥行きのある画像生成と多様なジャンルへの対応が可能となりました。
SDXL の特徴は以下のとおりです。
標準で1024×1024ピクセルの画像を生成
従来の Stable Diffusion のモデルより光源と影の処理などが改善
手や画像中の文字の表現、3次元的な奥行きのある構図などの画像生成AIが苦手とする画像も上手く生成できる
プロンプトの理解力も向上し、短いプロンプトでも高品質な画像を生成できる
大規模なパラメータ数で、35億のパラメータを有するBaseモデルと66億のパラメータを有するRefinerモデルから構成される革新的な新アーキテクチャに基づいて構築されており、オープンアクセス画像モデルの中でも最大級のパラメータ数を有する。
Refiner とは?
Refinerとは、画像生成においてSDXL Baseモデルと組み合わせて使う高画質化の技術です。
SDXL では、まず Baseモデルで画像の大まかな形や色を生成し、Refinerモデルは画像の細かい部分や質感を改善することができます。
つまり、Refinerモデルを使うことで、より綺麗で高品質な画像を生成することできるようになるわけです。
処理プロセスは以下の通りです。
一度 Baseモデルでプロンプトを通じてデータセットで画像データを生成
生成した画像データを縮小
縮小した画像とプロンプトをもとに、Refinerモデルのデータセットを使ってより精度の高い画像生成を行う

Refiner はこのようにして、画像を生成する際にBaseモデルとRefinerモデルをそれぞれ処理するので2Pass方式と呼ばれています。
従来の1Pass方式と比べると、圧倒的に品質が高く、より綺麗な画像が生成できます。
● Stable Diffusion の各バージョンの違い
Stable Diffusion には大き分けて3つのバージョンが存在します。
Stable Diffusion WebUI v1 (SD1.4 や SD1.5)
Stable Diffusion WebUI v2 (SD2.0 や SD2.1)
Stable Diffusion WebUI XL(SDXL0.9 や SDXL1.0)
よくそういったバージョン毎の違いをゲームのハードウェアに例えて比較することがありますが、PlayStation で例えると Stable Diffusion のバージョンの違いは以下のようになります。
Stable Diffusion WebUI v1 : PS3-512GB
Stable Diffusion WebUI v2 : PS3-1TB
Stable Diffusion WebUI XL : PS4-2TB
次の画像は、Stable Diffusionの各モデルがユーザーにどの程度評価されたかを示したグラフになります。
縦軸の値は、大きければ大きい程『ユーザーがどの程度、好みの画像を生成できたか?』を表しています。
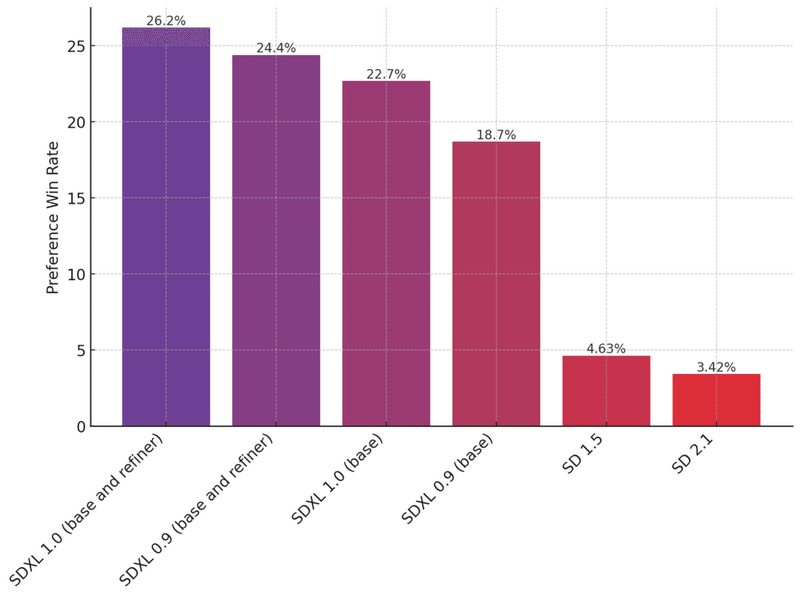
数値だけ見れば、SD1.5までは20回ほど生成しなければ好みの画像を生成することができませんが、SDXLでは4回に1回ほどは目的の画像が生成できることがわかります。
SDXLのパフォーマンスは既存のStable Diffusion 1.5や2.1を遥かに上回っており、ユーザーの好みに合った画像を生成する能力が高い といったことが良くわかります。
実際にSDXLで生成したイラストは以下になります。
このように、従来のStable Diffusion に比べて、SDXLの方がより細かいディテールや表情、色使いなどが豊かになっていることが分かります。

ただし、SDXL の方が全般的に優れているというわけではありません。
SDXL は新しい技術ですので、ControlNet の Inpatient や Tile など、既存の機能のうち、まだアップデートが追いついていないがために使用できないものもいくつかあります。
そのため、SDXL が最新版で優れているとはいっても、SDXL のみを使用するのではなく『SDXL で使用できない部分はSD 2.1系で使用する』といったように、双方併せて使用するのがベターかと思います。
● Stable Diffusionが画像を作るしくみ
こちらでは、Stable Diffusionが画像を作るしくみについて解説します。
なお、この仕組みについて詳細に説明すると論文 1 本分ほどの文章量になってしまうため、本稿では簡易的な説明に留めさせていただきます。予めご了承ください。
画像認識AI と 画像生成AI
画像生成AIとは、人間が見たり想像したりする画像をコンピュータが自動的に作成する技術のことで、画像認識AIとは逆の方向に働きます。
画像認識AI と 画像生成AI の違いは以下の通りです。
画像認識AI
画像に含まれる物体や人物や場面などを認識して、テキストやラベルなどに変換することができます。画像生成AI
テキストやラベルなどに書かれた内容や条件に従って、新しい画像を生成することができます。例えば、「猫」というテキストを入力すると、「猫」の画像を出力するという具合です。
画像生成AI では、事前に大量の画像とテキストのペアから学習することで、その関係性を学びます。このようにして作られたAIのことを「学習済みモデル」と呼びます。
学習済みモデルは、入力されたテキストやラベルなどを解釈して、それに適した画像を作成します。「Stable Diffusion」も、その一種です。
Stable Diffusion の 潜在的拡散モデル
Stable Diffusion では、潜在的拡散モデルという技術を用いて、画像を生成する過程を『ノイズの多い画像から少しずつノイズを除去していくという逆問題』として捉える方法で、文章からイラストを作ることができます。
つまり、Stable Diffusion では「プロンプト」と呼ばれる特殊な形式のテキストを入力し、それに対応した画像を描くことができます。
また、潜在的拡散モデルは、存在しない元画像を推測する能力が高いだけでなく、高品質かつ高速な画像生成が可能です。
例えば「photo of a japanese girl, light smile, sky」と入力すると、以下のように「空の下で笑っている日本人女性の写真」を生成します。

これは、画像生成AIが「ノイズが入った画像からノイズを消す訓練」をしているためです。AIは、意味のないノイズからでも文章に従って「本当はどんな画像か」を推測しながら画像を生成しています。
つまり、イラストからテキストとの関係を学習した「特徴・傾向」に沿って画像生成を行っている訳です。
注意点としては、拡散モデルが教師データの画像そのものを記憶しているわけではないことが挙げられます。
拡散モデルは、あくまでも教師データの画像とテキストのペアから学んだ「特徴・傾向」を記憶しています。例えば、「猫」というテキストから「猫」の画像を生成する場合、拡散モデルは「猫」の形や色や模様などの特徴や、「猫」が好む場所やポーズなどの傾向を記憶しています。そして、それらの特徴や傾向に基づいて、「猫」の画像を生成しているわけです。
つまり、拡散モデルは教師データの画像そのものを記憶しているわけではなく、画像の特徴や傾向を圧縮して記憶して「テキストとのペアから学んだ特徴・傾向に従ってイラストを生成している」という事が言えます。
Stable Diffusion の 画像生成の過程
Stable Diffusion の 画像生成は「Steps」と呼ばれる段階に分かれて行われます。ノイズから「本当はどんな画像か」を推測する過程を『Steps 1、Steps 2、Steps n…』と続けることで、より鮮やか・高画質なイラストが完成していきます。
先ほどの画像では、以下のような工程で生成されています。

各ステップごとで行われていることは、以下のように説明できます。
Steps 0
上記の画像の例では、AIがランダムなノイズ画像を用意し「空の下で笑っている日本人女性の写真となるようにノイズを消していってください」と命令されています。
この工程での作業を詳細に説明すると以下の用になります。元画像 x 0 を用意。
x 0 は、教師データとして与えられた画像の一つです。x 0 にノイズを加えて x t を作る。
t はステップ数で、t = 0 のときはノイズがなく、t = T のときは純粋なノイズになります。
このとき、ノイズを加える方法は様々ですが、一般的にはガウス分布やベルヌーイ分布などの確率分布に従って行います。x 0 を元画像 x t に近づけるように学習する。
x 0 から x t + 1 を予測するようにし、最終的に純粋なノイズ x T を与えます。この予測は、ニューラルネットワークやVAEなどの機械学習モデルを使って行います。
Steps 1, Steps 2, Steps 3, Steps n …
x T から逆拡散過程を行い、x T − 1 , x T − 2 , ⋯, x 0 の順に画像を生成します。このとき、テキストやラベルなどの指示を入力することで、生成される画像の内容やスタイルを制御できます。
上記の画像の例では、AIが学習した傾向と与えられたテキストに従って、ノイズを削除していき、「空の下で笑っている日本人女性の写真」に近づけようとします。そのため、ステップ数が増加するにつれて、だんだんと空や人間みたいなものが見えてきています。
Steps 35(最終ステップ)
x 0 を得ることで、最終的に拡散モデルによる画像生成が完了します。
以上がStable Diffusion で拡散モデルを用いて画像生成する際の仕組みです。
● 必要なマシンスペック
『画像生成AI』と聞くと、『高い処理性能のPCが必要なんじゃないか?』と思う方も多いと思います。
実際、Stable Diffusion で画像生成をするためには13〜30万円ほどのハイスペックなPCに Stable Diffusion WebUI をインストールする必要があります。
そのため、本稿では後述する『クラウドサービスを利用してインターネット上から利用する方法』を推奨していますが、ここでは、Stable Diffusion WebUI で画像生成をする際において必要なマシンスペックについて解説していきます。
Windows, Mac 別で必要なグラフィックボード (GPU) のスペック
Windows
NVIDIA製のPascal世代以降のGPU(GTX1000番台以降)でVRAMが8GB以上のものが必要です。
できれば、GeForceRTXシリーズの 3000番台以降で、VRAMが16GB以上のものが良いです。Mac
M1 以上のものが必要です。
Intel製のMacbook だと、かなりStable Diffusion WebUI の利用に制限があります。
VRAM とは?
VRAM(ビデオメモリ)とは、グラフィックボードに搭載されているメモリのことです。VRAMは、ゲームやビデオ編集などのグラフィック処理や高度な演算処理に必要なデータを一時的に保存する役割を果たします。
つまり、このVRAMの容量が大きいほど、高解像度や高品質の画像をスムーズに生成できます。
反対に、VRAMの容量が小さいほど、Stable Diffusion WebUI で画像生成する際の計算をするスペースが足らなくなり、画像生成そのものを行うことができなくなります。
ちなみに、VRAMは システムメモリ(RAM)とは異なります。システムメモリは、CPUが使用する一般的なデータの保存に活用されますが、GPUのVRAMは、主にグラフィックに関するデータを保存するので、高速でかつ広いバンド幅を持っています。
VRAMの容量は グラフィックボードの種類やメーカーによって容量が決まっておりますので、以下にグラフィックボードの種類毎のVRAMの容量と、Stable Diffusion WebUI を使用する上で受ける制限について代表的なものを記載します。
▫ GeForce RTX 3070 (VRAM:8GB)
できること
Stable Diffusion2.1(以下 SD2.1)系前までの学習モデルを使用して基本的な画像生成をする
できないこと
SD2.1系前までの学習モデルと後述する LoRA や ControlNet などを併用した画像生成(設定による)
LoRAの追加学習
Stable Diffusion XL(以下 SDXL)の学習モデルを使用した画像生成(設定による)
これらに加え、画像生成をする際に速度を犠牲にVRAMの計算量を減らし、低速で生成しなければならないケースもあります。
また、Stable Diffusion WebUI の設定の遺憾によっては画像のアップスケールや並行処理での画像生成などをする場合、画像生成そのものができません。
▫ GeForce RTX 3060 (VRAM:12GB)
できること
SD2.1系前までの学習モデルと LoRA や ControlNet などを併用した画像生成
SD2.1系前までの学習モデルを使用したLoRAの追加学習
Stable Diffusion XL(以下 SDXL)の学習モデルを使用した基本的な画像生成(設定による)
できないこと
SDXLの学習モデルと LoRA や ControlNet などを併用した画像生成(設定による)
SDXLの学習モデルを使用したLoRAの追加学習
このように、基本的には SDXL の学習モデルを使用したStable Diffusion WebUIの利用に制限があります。
▫ NVIDIA RTX A4000 (VRAM:16GB)
できること
SD2.1系前までの学習モデルと LoRA や ControlNet などを併用した画像生成
SD2.1系前までの学習モデルを使用したLoRAの追加学習
SDXLの学習モデルと LoRA や ControlNet などを併用した画像生成(設定による)
SDXLの学習モデルを使用した簡単なLoRAの追加学習
できないこと
SDXLの学習モデルを使用した複雑なLoRAの追加学習
このように、VRAMが16GB以上の場合、Stable Diffusion WebUI でほとんどの機能を利用する事ができます。
必要なマシンスペックのまとめ
本稿ではグラフィックボードにフォーカスして解説してきましたが、Stable Diffusion WebUI を使用するに当たって最低限必要なマシンスペックをまとめると、以下のようになります。
OS:Windows10 or 11 (64bit版) / Mac OS Ventura 13.6.0 以降
CPU:Intel Core-i5 以上・AMD Ryzen 5 以上
RAM(メインメモリ):16GB以上
GPU(グラフィックボード):NVDIA製GPU VRAM 16GB以上
ストレージ:SSD 256GB以上
ちなみに、このスペックのPCを使用しようとすると 30万円ほどの費用がかかります。もし上記のスペックのPCを持っていない場合、初期費用としてかかってくるわけですが、実は後述するクラウドサービスを使用することで、たとえどんなPCを使っていたとしても、インターネット上から無料でStable Diffusion WebUI を使用することも可能です。
また、私の所管では、VRAM12GBのグラフィックボードを使用をして Stable Diffusion WebUI を利用しているユーザーが多い印象がありますが、これはそのスペックのPCであれば13〜16万円ほど、グラフィックボード単体だと4〜5万円台で購入できるためです。
しかし、VRAM12GB ですと SDXL の使用にかなりの制限があるので、 本稿では VRAM 16 GB以上のグラフィックボードの使用を推奨しています。
● Stable Diffusion WebUI を使う方法
現在、Stable Diffusion WebUI を使用するには大きくわけて2パターン、さらに細分化すると全部で4つの方法があります。
結論からお伝えすると、本稿では
1.Amazon Sagemaker Studio で無料利用。
2.Paperspace Gradient で課金し、より高性能なGPUマシンで利用。
3.それでも物足りなくなったらハイスペックPCを購入する。
といった優先順位での利用を推奨しております。
ここでは、それぞれどのような人がどの方法を使えば良いのかの詳細を解説していきます。
① 自分のPCにインストールする方法
こちらは、『● 必要なマシンスペック』で解説したマシンスペックのPCを持っていて、かつプログラミング知識のある人向けになります。
自分のPCで使用するには、Python(version 3.10.6 を推奨)と Gitをインストールする必要があり、お手持ちのPCの環境によってもインストール方法が異なりますので、インターネット上の文献の中からご自身の環境に併せた方法を調べてインストールするといった手順になります。
この場合のメリットとしてはStable Diffusion WebUI の拡張やクラウド環境では使用できない、ローカル環境ならではの機能を利用できる点が挙げられますが、Stable Diffusion WebUI や 拡張機能のエラーが出た際にも自身のPC の環境によるエラーの場合もありますのでその対応力が必要になります。
そのため、M1以上のMacbookか、NVIDIA製GPU(VRAM16GB以上)の ハイスペックなPCを持っており、プログラミング知識もある場合のみ推奨する方法になりますので、あまり多くの人にはおすすめしておりません。
② クラウドサービスを利用する方法
こちらの方法は、クラウドサービス上の環境を使用して、GPUマシンやStable Diffusion WebUI の利用をする方法になります。
『① 自分のPCにインストールする方法』を使用する場合、通常は 30万円ほどの初期投資が必要になりましたが、クラウドサービスを使用すればオンライン上でGPUを借りることができるので、たとえどんなPCを使っていたとしてもインターネットに接続できさえすれば、誰でも無料 または 低コスト で簡単にStable Diffusion WebUI を使用してAI画像生成を行うことができます。
また、この場合は使用する環境がみな一緒になりますので、煩わしい Stable Diffusion WebUI の導入から起動までの作業をわずかワンクリックで実行することも可能です。
また、クラウドサービスには無料のものから月額8$(約1180円)のものがありますが、たとえ有料プランを使用したとしても、PCを購入する場合の13〜30万円の費用と比較すると、ランニングコスト的にはその約10~20年分と、かなりコスパが良い事がわかります。
また、GPUに関しても、規模の経済の原理で13〜16万円のPCよりも性能が高いものが使えます。
つまり、GPUを使用できるクラウドサービスを使用したほうが、コスパが良く、より性能の高いGPU を使うことができます。
▫ 【非推奨】 Google Colab でインストールする方法
Google Colab はnotebook上で無料でGPUを使用できるクラウドサービスです。
今まで、『無料でStable Diffusion を始めたい。』といった方にまず最初におすすめしていましたが、2023年5月から無料プランで Stable Diffusion WebUI の利用ができなくなりました。
そのため、現在は Stable Diffusion WebUI を使用する場合、月額1179円の課金が必要になりますが、有料プランであっても無料利用時間のようなものがあり、Stable Diffusion WebUI を利用する上ではほぼ従量課金性のようになっているため、使用すればするほど利用料金がかかるようになっています。
というのも、Google Colab の有料版のプランでは、コンピューティングユニットという単位で計算資源を消費します。コンピューティングユニットは、定期購入や追加購入で入手でき、Colab Pro では、月額で 100 ユニットが付与され、90 日間有効です。
コンピューティングユニットの消費量は、使用する GPUマシン やメモリの種類や量によって異なりますので、ハードな使い方をするとすぐに利用できなくなる場合もあります。
GPUマシンのスペック的には、VRAMは15GB、ストレージは共有フォルダなどで利用していなければ15GB まで使用できますが、私は3〜4日ほどで全てのコンピューティングユニットを使い果たしました。
コンピューティングユニットの詳細は下記をご覧ください。
▫ 【無料】 Amazon Sagemaker Studio でインストールする方法
こちらは、『ハイスペックなPCは無いけれど、とりあえず無料でStable Diffusion WebUI を試してみたい。』『マネタイズできるまでは無料で使いたい。』といった方向けになります。
Amazon Sagemaker Studio は、Google Colab 同様、notebook上で無料でGPUを使用できる、クラウドベースの機械学習開発環境です。
Stable Diffusion を利用するために必要なライブラリやモデルが事前にインストールされており、すぐに画像生成を始めることができます。
アカウント作成に1時間(以前は半日〜2日)ほど要しますが、Stable Diffusion WebUI を利用する場合でも、無料で利用できます。
なお、1日に利用できるCPUは8時間、GPUは4時間です。
VRAMは15GB、ストレージは25GB まで使用できます。
以下では、Amazon Sagemaker Studio で Stable Diffusion WebUI をワンクリックで使用する方法を詳細に解説しており、最新版モデルであるSDXLを使用して AI画像生成を行うことができます。また、一日4時間の使用制限を実質ないことにする方法も紹介しておりますので、『これからStable Diffusion WebUI を使用して画像生成をしてみたい』といった方は、是非ご一読ください。
▫ 【月額8$】 Paperspace Gradient でインストールする方法
こちらは、『月額1180円程度の利用料金なら気にしない。』『月1180円以上のマネタイズができている。』『Amazon Sagemaker Studio よりも高性能なGPUを使いたい』といった方向けになります。
Paperspace Gradient は、Google Colab や Amazon Sagemaker Studio に似た、クラウド上でGPUを利用する事ができるサービスになります。
特徴としては、従量課金性ではなく Proプランであれば月額8$(約1180円)でGPU が一日に何時間でも使い放題となることが挙げられます。
また、使用するGPUマシンにもよりますが、VRAMは16GB、ストレージは15GB まで使用できます。
以下では、Paperspace Gradient で Stable Diffusion WebUI をワンクリックで使用する方法を詳細に解説しており、こちらも最新版モデルであるSDXLを使用して AI画像生成を行うことができます。また、初月無料で利用する方法や15GBのストレージ制限を実質ないことにする方法も紹介しておりますので、『もう一歩踏み込んでStable Diffusion WebUI を使ってみたい』といった方は、是非ご一読ください。
● Stable Diffusion WebUI を使用する基本的な流れ
Stable Diffusion WebUI を使用するには、基本的には以下の手順を踏むことで導入から画像生成までを行うことができます。
Stable Diffusion WebUI のリポジトリをクローン
こちらは Git で『https://github.com/AUTOMATIC1111/stable-diffusion-webui』のリポジトリをクローンします。学習モデルのダウンロード
後述する Hugging Face や CivitAI などから、Stable Diffusion WebUI で画像生成に使用するモデルをダウンロードします。launch.py ファイルを実行
『python launch.py』などとし、実行することで Stable Diffusion WebUI が起動されます。画像生成を行う
txt2img や img2img タブでプロンプトを入力し、ステップ数やサンプリングアルゴリズムなどを設定した後、Generateボタンを押下して画像生成します。
なお、先程ご案内した以下の記事ではこれらの作業をワンクリックで実行できるようにしておりますので、本稿では手順の詳細は省略します。
● 【重要】 Stable Diffusion Web UI の画面説明 (txt2img)
上記の記事からStable Diffusion Web UI を起動すると、下記の操作画面が表示されます。
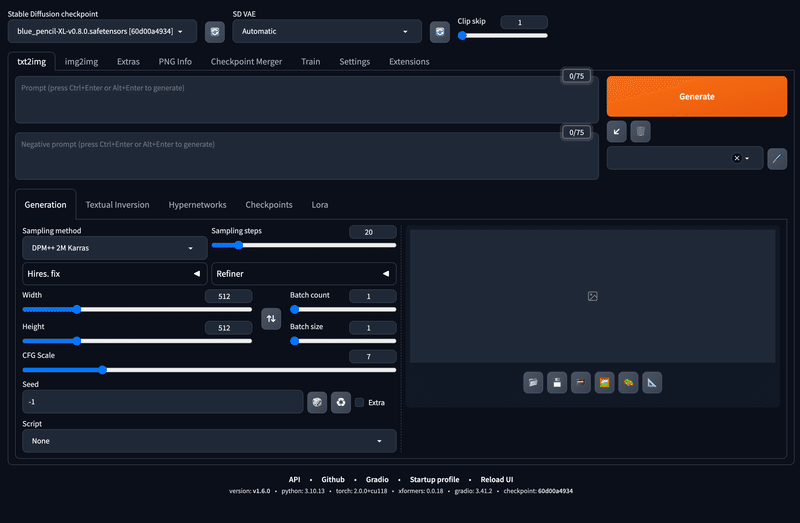
ここでは、txt2img のタブを例に、こちらのパラメーターについて詳しく解説していきます。
なお、Stable Diffusion WebUI においては、こちらで説明するパラメーターの項目が全ての基本となりますので、 こちらを理解しているのとしていないのとでは、生成される画像品質や生成功率が段違いになります。
本稿においてもかなり重要な部分になりますので、 私も詳細な記述になるよう努力いたしました。わからない点があればコメント欄で教えてください。
なお、 学習モデルやVAE といった、各モデルの保存先や探し方については『● 学習モデルの探し方とライセンス > 各モデルのダウンロード先』 で 詳細に解説を行っておりますので、このチャプターでの説明は省略いたします。
画面のパラメーターの説明 (Generationタブ)
以下のように、画像に番号と簡単な説明文を加えておきましたので、ここではこちらの画像をもとに説明を行っていきます。
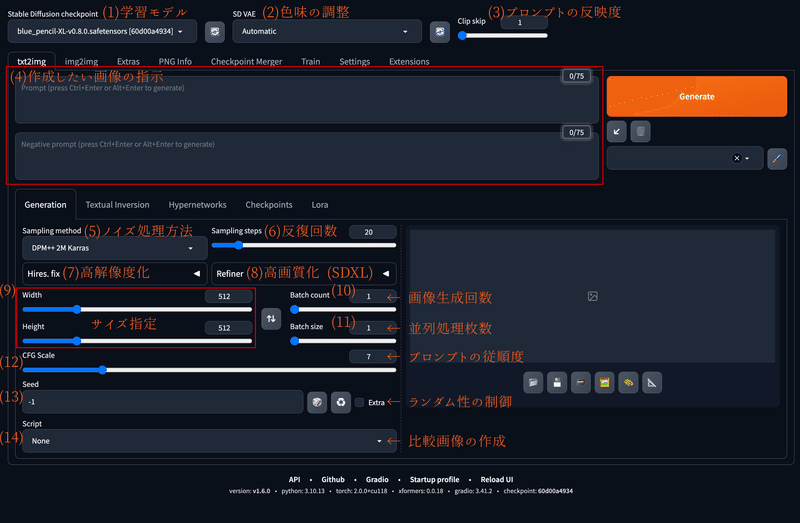
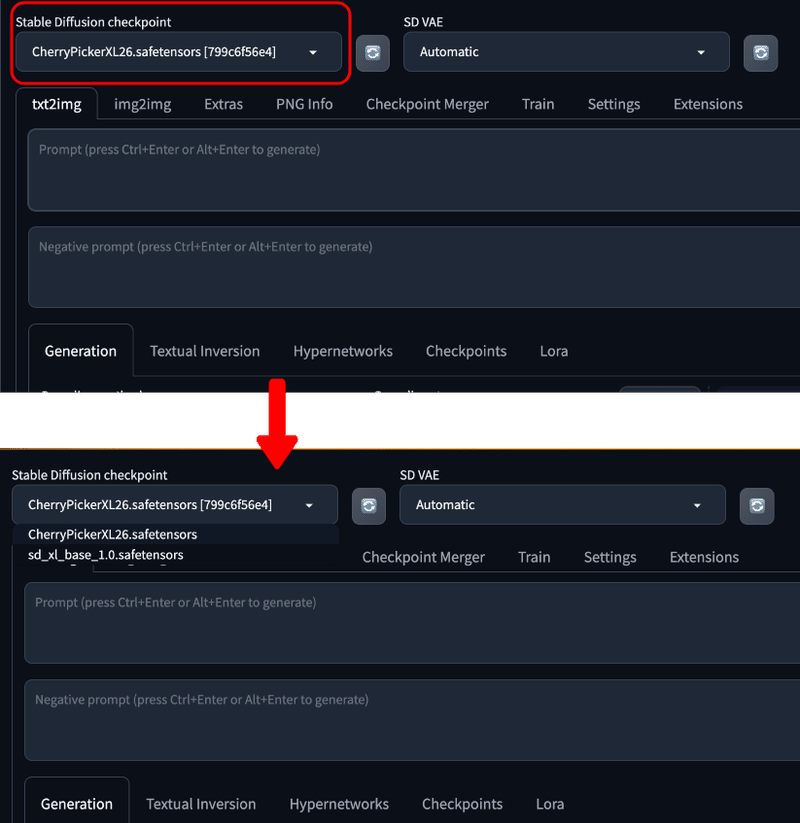
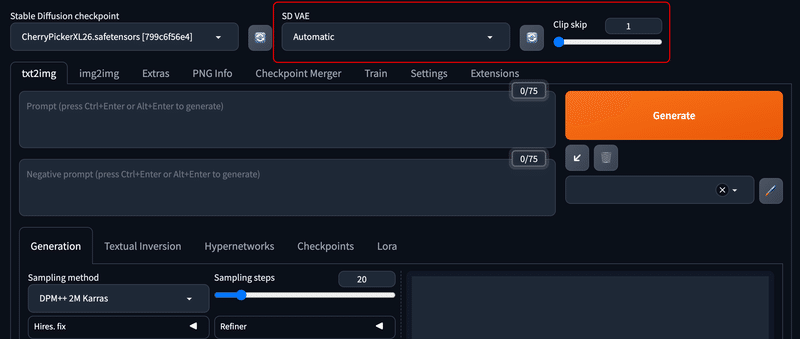
(1) Stable Diffusion checkpoint (学習モデル)
こちらでは使用する学習モデルを選択します。 学習モデルとはAIが画像生成をするために学習したもので、様々な種類やスタイルの画像を作ることができます。
Stable Diffusion WebUI では、学習モデルは「Checkpoint」や「Model」のように呼ばれ、学習させたデータセットによって生成できる画像の特徴や種類が異なります。データセットとは画像とテキストのペアからなる大量のデータのことです。
つまり、AIはこのデータセットを使ってテキストに対応する画像を生成する方法を学習し、それに従って人物や動物・風景・2Dイラストなどの画像を生成します。学習モデルによって得意不得意な画像があるのはこのためで、どんなモデルを使うかによって、Stable Diffusion WebUI で生成される画像の品質や雰囲気は大きく変わるということになります。
SDXLの学習モデルは「.ckpt」や「.safetensor」という拡張子で、現在は「.safetensor」が主流です。また、一つあたり約6.4GBといった非常に大きなサイズになりますので、Amazon Sagemaker Studio Lab を始めとする GPU サービスでダウンロードできるモデルファイル数は基本的には 1〜2 個までとなります。つまり、場合によっては都度消したりダウンロードしたりといった作業が必要になります。(こちらの記事で Paperspace Gradient というものを紹介していますが、何個でも学習モデルをダウンロードできる裏技もあります。)
モデルは、以下のように赤枠の部分をクリックするとダウンロードしたモデルの一覧が表示され、使用するものを選択することができます。
(2) VAE
VAEとは、Variational Autoencoderの略で、Stable Diffusionやその派生モデルにおいて、画像の品質や色彩を調整する役割を担っています。
拡散モデルの画像生成AIには、『テキストエンコーダ、U-NET、VAE』の三つのモジュールがあり、各々を簡単に説明すると以下のようになります。
テキストエンコーダ
人間が書いたプロンプトをAIが理解できる形に変換する。U-NET
プロンプトに基づいて潜在空間と呼ばれる特殊な空間で画像を描く。VAE
画像を潜在空間から通常の空間に移す際に、画像の見た目や色味を変える。
よって、VAEを変えると、同じプロンプトでも色合いや見栄えなどが少し違う画像が生成されます。
VAEのモデルの種類は学習モデルほど多くはありませんが、色々な種類があります。
大抵の場合、学習モデルに合わせて作られたり付属されている場合が多いですが、使用するのとしないのでは『目のハイライトの入れ方が違う』などの生成画像に若干の変化がありますので、色味や明るさなどが気に入らない場合は、別のVAEを試してみると良いです。
有名どころでは、SD2.1以前のモデル用のものだと『kl-f8-anime2』や『vae-ft-mse-840000-ema-pruned』、SDXL用ですと『sdxl_vae』などがあります。
ここでは参考として、SD2.1以前のモデルを使用して、上記のVAEの比較画像を作成しました。

このように、SD2.1以前のモデルとSDXL のVAEを使用するとするとエラーになり真っ黒な画像が表示されるか、もしくは色味がとても崩れた画像が表示されます。
以下は、SDXL で『vae-ft-mse-840000-ema-pruned』を使用した際の例になります。このように、ノイズ混じりの画像が表示されます。

キャラクターの画像で比較すると、以下のようになります。

ちなみに、SDXLにおいては VAEを適用してもしなくても画像の品質にほとんど変化がないと言われています。
本稿では、参考として以下の比較画像を作成しました。

(3) Clipt Skip
Stable Diffusionでは、設定されたプロンプトの情報を12層のレイヤーで処理して画像を生成します。
簡単に説明すると、以下のように12個のレイヤーでそれぞれ連想ゲームのような事をしている構造になっています。
レイヤー1が『 人』 であると、レイヤー2では『 男性 』や『 女性』となる。
レイヤー2で『 男性 』を選ぶ経路を辿ったとする と、レイヤー3で『 男性、少年、青年、父親、祖父』となる。
~ 中略 ~
レイヤー12で終了
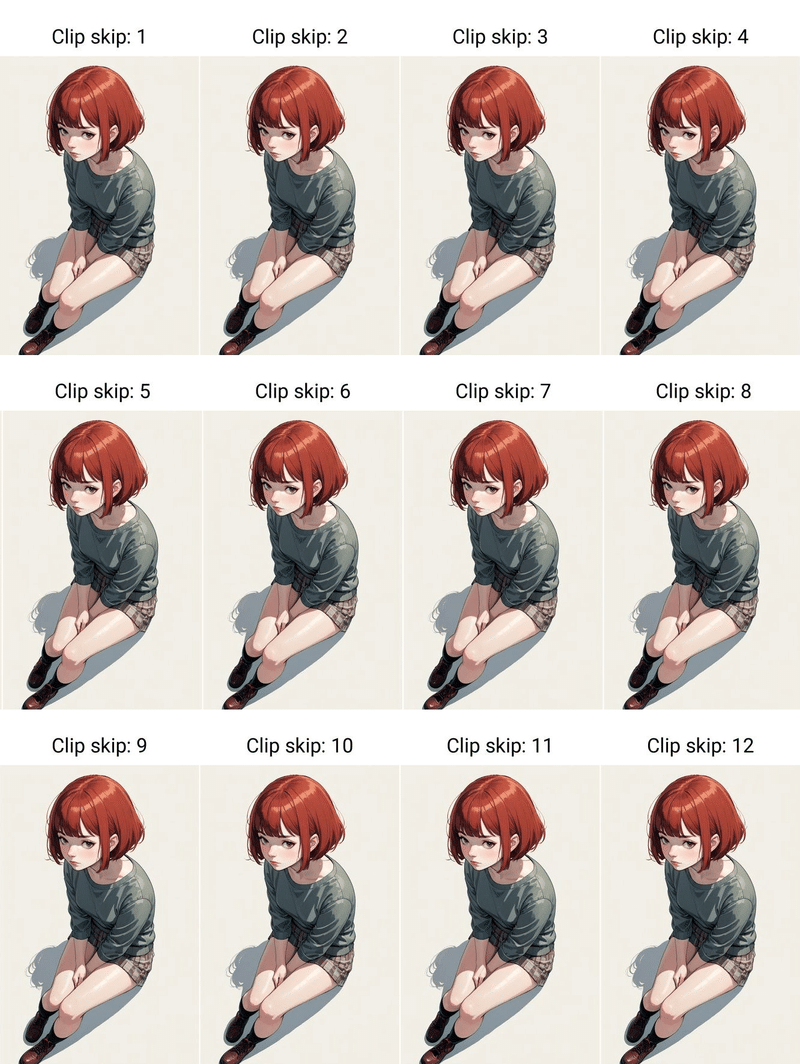
Clip skipは、これらの12層のレイヤーのうち最後から何枚目のレイヤーを使用するか選択できるものになります。
例えば、Clip skip の値が1のときは12層全てのレイヤーを通過しますが、値を2にすると最後のレイヤーをスキップしてレイヤー11までを使用して画像生成を行います。
つまり、このClip skipの値が低いほどプロンプトの情報量が多くなり、その結果『プロンプトの反映度が高くなる』わけです。
反対に、Clip skipの値が高いほど、プロンプトの情報量が少なくなり、プロンプトの反映度が低くなります。
このClip skipの値も、モデルによって推奨値が決められていることが多く、SD 2.1以前のモデルだとClip skip2を推奨するものが非常に多いです。
なぜそのようにレイヤーを早い段階で停止する必要があるのかと言うと、レイヤーが深くなるにつれて生じる『 マイナーな情報』の影響を減らして画像生成を行うためです。
例えば『 牛』という画像を生成したいとすると、レイヤーが深くなるにつれて牛のサブカテゴリである『 アンガス牛』などが含まれる事があります。
つまり、あえて最後のレイヤーまでを実行せずに途中で切り上げることによって、意図しない情報が生成結果に含まれてしまうことを防いでいるわけです。
SD 2.1以前のモデルでClip skipを調整した際の例は以下をご参照ください。

また、SDXL の場合は Clip skipの値は特に関係ありませんが、多くは『1』を設定することが推奨されています。
SDXLの場合の比較画像は以下になります。
(4) プロンプトとネガティブプロンプト
▫ プロンプト
プロンプトとは AIに「どんな絵を描いてもらいたいかを伝えるための文章」のことです。基本的には英語で、以下の部分に入力します。

『● Stable Diffusionが画像を作るしくみ > Stable Diffusion の 画像生成の過程』で解説した画像のプロンプトを例に出すと、『photo of a japanese girl, light smile, sky』(空の下で笑っている日本人女性の写真)という画像を作ってもらいたい場合は、単語や文章を「,」(カンマ)でつなげた独特な書き方でその内容を文章化してAIに伝えます。
すると、AIはそのイメージに近いものを生成してくれます。
SDXLの場合は自然言語処理にも特化しているため、翻訳ツールで翻訳した英文をそのまま使用する事もできます。
▫ Negative Prompt (ネガティブプロンプト)
ネガティブプロンプトとは、プロンプトとは逆にAIに「どんな画像を作ってもらいたくないかを伝えるための文章」のことです。
以下の部分に入力します。
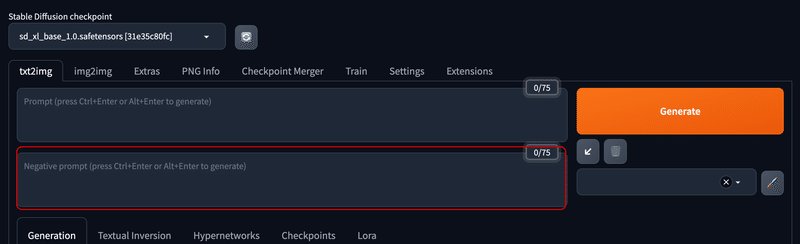
例えば、ネガティブプロンプトに『worst quality, low quality』(最低品質、低品質)のように記述すると、低画質な画像が出力されにくくなります。これを応用して、以下のように入力するとリアル系の画像が出力されやすくなるようにすることができます。
プロンプト:『photo of a japanese girl』(日本人の女の子の写真)
ネガティブプロンプト:『paintings, sketches』(絵画、スケッチ)
プロンプトの詳細の書き方やコツは以下で説明しておりますので、クリックしてご参照ください。
(5) Sampling method (サンプラー)
Sampling method とは、AIが画像生成に用いるノイズの処理方法のことです。ノイズとは『● Stable Diffusionが画像を作るしくみ > Stable Diffusion の 画像生成の過程』で 解説した通り、画像にランダムに加えられる小さな変化で、画像の多様性や学習モデルの特徴を引き出す役割があります。
Sampling methodは、『サンプリングアルゴリズム』や『Sampler(サンプラー)』などと呼ぶこともあります。
Stable Diffusion WebUI における画像生成では、このサンプラーによるノイズの加え方によって画像の生成速度や品質・雰囲気などが大きく影響されます。
サンプラーには様々な種類があり、それぞれに特徴やメリット・デメリットがあります。例えば、「DPM++ 2M Karras」は軽くて高品質、「DPM++ SDE Karras」は重い反面、大変品質の良い画像が生成できるといった特徴があります。
また、サンプラーは同じプロンプト・設定でもサンプラーによって画像の作り方が違うため、学習モデルによって推奨されるものが異なります。
つまり、モデルに推奨されているステップやCFGスケールなどの設定とサンプラーの設定が合わないと、作画が崩壊する場合もあるのです。
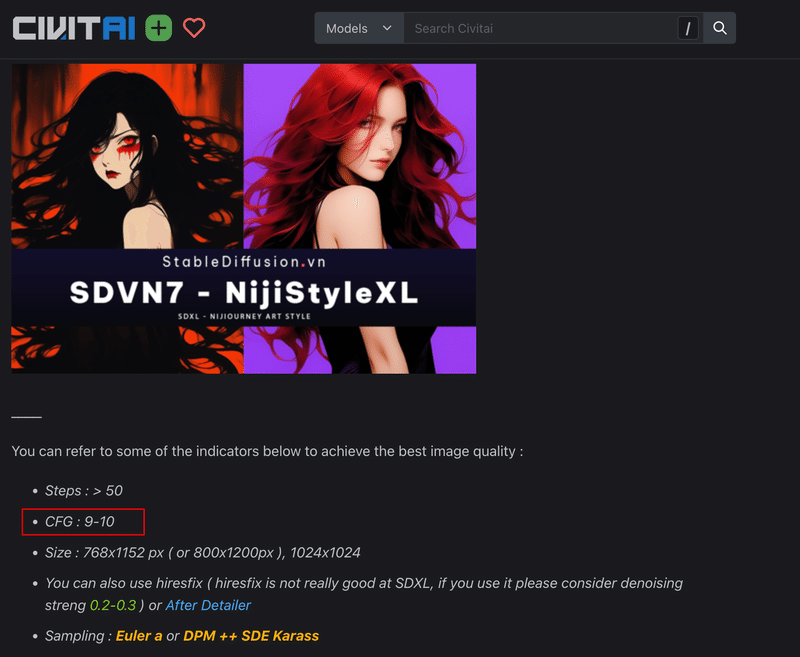
例えば以下は『SDVN7-NijiStyleXL』というモデルの推奨設定欄の画像ですが、推奨されるサンプリングアルゴリズム に『Euler a or DPM++ SDE Karass』との記載があります。

▫ サンプリングアルゴリズムの比較
Stable Diffusion WebUI v1.6.0 で使用できるサンプリングアルゴリズムには、以下の種類があります。全てで30種類です。

サンプラーの違いを実感するために、さきほどの SDVN7-NijiStyleXL というCheckpointを用いて、サンプラーごとの比較を行います。
今回使用したプロンプトや設定は下記になります。
Model: SDVN7-NijiStyleXL
Prompt: anime,realistic,sketch,1girl,lip,Sweater,order,Blue gradient background,Neon hair,Textured crop,Canadian,(masterpiece,best quality,niji style)
Negative prompt: worst quality, low quality,realistic,illustration, 3d, 2d, painting, cartoons sketch
Steps: 40
CFG scale: 10
Seed: 2427071359
Size: 836x1254
この設定で、全30種類のサンプリングアルゴリズムを比較した画像が以下になります。
推奨設定の通り『 Euler a ・ DPM++ SDE Karass 』では、他の Sampler と比較して構図の崩れが無いことがわかります。

このように、同じプロンプト・設定でも使用するサンプラーによって生成される画像が異なり、学習モデルによっては推奨されるサンプラーを使用することによって、より高品質な画像を生成しやすくなります。
(6) Sampling steps (ステップ数)
ステップとは、AIが画像生成をするときにサンプラーによるノイズを除去する作業を繰り返す回数のことです。
一般的には、ステップ数が多いほど、画像生成に時間がかかる代わりに生成画像の画質が向上します。
ここで『● Stable Diffusionが画像を作るしくみ > Stable Diffusion の 画像生成の過程』で説明した『photo of a japanese girl, light smile, sky』(空の下で笑っている日本人女性の写真)の画像を例を流用しますが、ステップ 1 では、まだノイズが多く画像がぼやけており、ステップ数が増えるごとにノイズが減り画像が鮮明になっていることがわかります。

注意点としては、ステップ数を変更すると生成される画像も変化することが挙げられます。なぜかというと、Stable Diffusion WebUI では、Sampling steps で指定したステップに収束するように画像からノイズを除去していき画像を生成します。
そのため、以下のように、Sampling steps を変更した場合、同じ設定で画像生成を行っても生成される画像に差異が生じます。

また、このようにステップ数を増やすことで画像の品質が高くなりますが、ステップ数を増やせば増やすほど画像の品質が良くなるわけではありません。上記の比較画像を見ても分かるように、画像の品質自体はステップが増えるごと徐々に変化が少なくなっていきます。
つまり、生成時間はどのステップ毎でも一様ですので、生成時間に対して得られるメリットが段々と少なくなっていくということになります。
ステップ数に関しては、SDXL であればテスト用なら10〜20 ほど、本番用なら 40〜60 程度が良いと言われています。
SD2.1以前のモデルであれば、10くらいでテストをして、本番用は20〜30程度で生成するのが良いかと思います。
(7) Hires.fix
Hires.fix は高解像度補助とも呼ばれており、生成画像に対して高解像度化を行ったり画像の書き込み(ディティール)を追加したりする際などに使用します。生成した直後に高解像度化を行うため、時間を要する代わりに高品質な画像を生成することができます。
Extra タブとの違いとして、Extra タブでは高解像度化のみを行いますが、Hires.fix はディティールを追加しながら高解像度化を行えるといった点が挙げられます。
プルダウンを開くと、以下のように Hires.fix の設定パネルが表示されます。
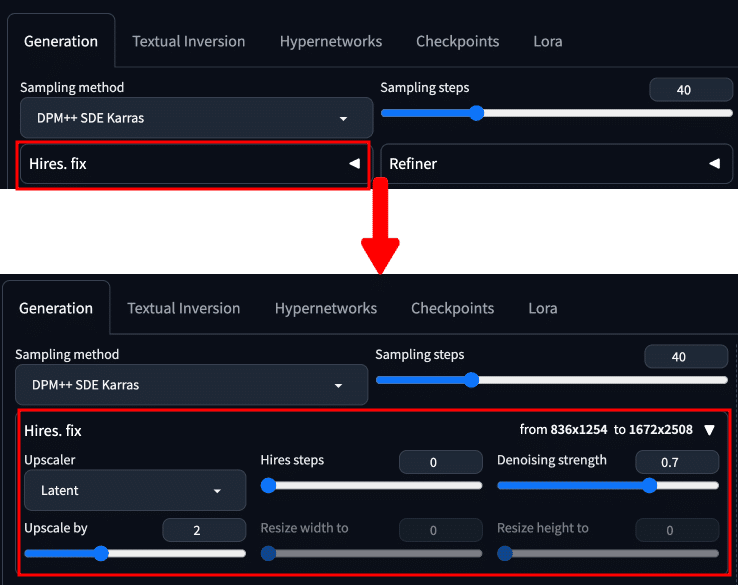
以下のモデルやプロンプト・設定を用いて、それぞれのパラメーターについて解説します。
1girl, short hair, white hair, expressionless, business_suit, hands in pockets, looking_afar, wallpaper, portrait, from side, flat shadow, lens flare, simple background, (artwork in the style of Adrian Tomine Dave McKean Meobius:1.4), lora:ClearHand-V2:1
Negative prompt: (worst quality, low quality:1.3), lowres, bad anatomy, bad hands, missing fingers, extra digit, extra arms, extra hands, fewer digits, artist name, signature, watermark, nsfw, unaestheticXL_Sky3.1
Steps: 40, Sampler: DPM++ SDE Karras,
CFG scale: 7, Seed: 2733558891, Size: 836x1254,
Model hash: 60d00a4934, Model: blue_pencil-XL-v0.8.0,
Variation seed: 957137061, Variation seed strength: 0.05,
Lora hashes: "ClearHand-V2: a20159a58523", Version: v1.6.0
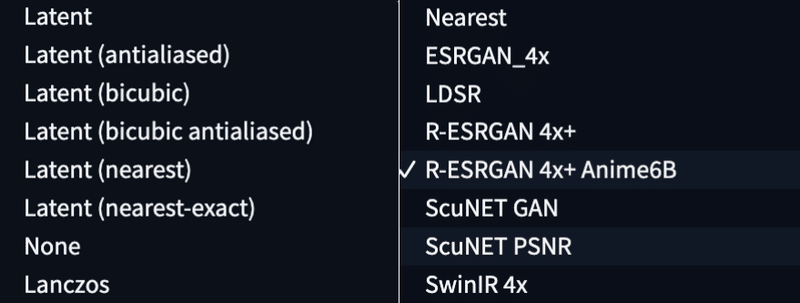
▫ Upscaler
高解像度化に用いるアルゴリズムになります。アルゴリズムにはデフォルトでは以下のアルゴリズムがあります。
イラスト系の画像であれば『R-ESRGAN 4x+ Anime6B』フォトリアル系の画像の場合は『SwinIR_4x や R-ESRGAN 4x』 が良いとされています。
▫ Hires steps
こちらは、Hires.fix で高解像度化する際のStep数になります。この数値が大きければ大きいほど緻密になりますが、生成に時間も要します。
デフォルトでは『0』となっていますが、0 の場合はメインパネルのサンプリングステップ数と同様の Step数を適用します。
以下は Hires steps を 0〜40 に設定し、10 Steps ごとに生成した画像の比較になります。今回はさほどの違いはありませんが、設定値の目安としては 20〜40 ほどが適切であると言われています。(1.4倍にアップスケールしています。)

▫ Denoising strength
こちらは、生成した画像に対してどの程度ノイズを加えてから高画質化を行うかといった設定項目になります。Stable Diffusion WebUI では画像からノイズを除去していくことによって画像生成を行いますので、この値が大きいほど元画像からかけ離れた画像を生成します。
つまり、Denoising strength を大きくすれば、元画像からかけ離れた画像になる代わりに画像に対する書き込みは増えるということになります。
以下は Denoising strength を 0.2〜0.8 に設定し、0.2 ごとに生成した画像の比較になります。Denoising strength(Denoising)の値が大きくなるにつれて、元画像からの変化や書き込みが多くなる傾向が見て取れます。

Denoising strength の設定値に関しては、まずはデフォルト値の 0.7 で試してみるのが良いと思われます。
▫ Upscale by
こちらでは元画像を何倍にアップスケールするかといった倍率の設定を行うことができます。
Upscale by を『1.4』に設定している場合、パネルの左上にアップスケール後のサイズが表示されます。今回の場合は元画像のサイズを『836 x 1254』に設定してあるので『from 836x1254 to 1170x1755』と表示されます。

Upscale by に関してもメインパネルの Width・Height と同様、大きさを変更すると生成される画像も変化します。
以下は Upscale by を 1.1〜1.4 に設定し、0.1 ごとに生成した画像の比較になります。あまり大きい数値を設定すると『OutOfMemoryError』というVRAMが足りないという旨のエラーが発生するので、まずは 1.2〜1.4 あたりから様子を見ていくのが良いかと思われます。

(8) Refiner
『● Stable Diffusion XL 1.0 (SDXL) とは? > Refiner とは?』でも解説した通り、Refinerとは、画像生成においてSDXL Baseモデルと組み合わせて使う高画質化の技術です。
基本的には、Baseモデルで生成した画像に対し、Refinerモデルで画像の細かい部分や質感を改善します。
Refiner を使用するには、以下のRefiner の学習モデルをダウンロードしておく必要があります。
ダウンロードが完了したら、『<Stable Diffusion WebUIのフォルダ>/models/Stable-diffusion』にファイルを配置して下さい。
Stable Diffusion WebUI でRefiner を使用するためには、以下のプルダウンを開きます。

すると、以下のように展開されます。
このようにして Refinerの項目を展開していない場合は、Refiner は適用されません。

▫ Switch at
ここで、『● Stable Diffusion XL 1.0 (SDXL) とは? > Refiner とは?』で解説した以下の説明を思い出して下さい。
Refinerの処理方法
一度 Baseモデルでプロンプトを通じてデータセットで画像データを生成
生成した画像データを縮小
縮小した画像とプロンプトをもとに、Refinerモデルのデータセットを使ってより精度の高い画像生成を行う

Stable Diffusion WebUI では、このように画像生成の途中でBaseモデルから Refiner に切り替わりますので、そのタイミングを 『Switch at』という値で設定します。
Switch at の初期値は0.8なので、画像生成が80%のタイミングでRefinerモデルに切り替わります。 つまり、Switch at に 1 を設定している場合は Refiner は適用されません。
以下は、実際にSwitch at の値を変更してRefinerを適用させた比較画像になります。
『20%, 40%, 60%, 80%, 100% (未使用)』といったように、Refiner に切り替えるタイミングによって生成結果に差異が生じています。

Switch at の値についてですが、使用するモデルにもよりますが大体 0.6〜0.8 の間が最も良い生成結果が得らると言われています。
ちなみに、今回使用した学習モデルやプロンプト等は以下になります。
Model: CherryPickerXL
Prompt: highres,best quality,photo,natural, deep dark fantasy cat kawaii mochi mochi wani wani panic
Negative prompt: bad quality,worst quality,illustration,girl
Sampler: DPM++ SDE Karras
Steps: 20
CFG scale: 7.5
Seed: 2094132780
Size: 896 x 1280
▫ Refiner の注意点
Refiner の注意点として、適用させれば必ずしも良い生成結果が得られるとも限らないということが挙げられます。
以下は『blue_pencil-XL-v0.8.0』というイラスト系のデータセットを学習したモデルを使用した際の例ですが、参考画像のように、使用するBaseモデル(学習モデル)やプロンプトなどによっては Refiner を使用することによって品質が悪化する場合があります。

また、上述した猫の画像の例のように、イラスト系よりもリアル系の方が Refiner の効果が現れやすい傾向があります。
なお、リアル系の画像を出力する場合に関しても、モデルのデータセットがイラスト系によっていると、 Refiner を適用した結果、イラスト系の画像に寄ってしまう傾向があります。以下の比較画像は『sdvn7Nijistylexl_v1』を使用した際の例です。

先程の猫の画像で比較した画像は『CherryPickerXL』というリアルフォト系の画像を学習したモデルになりますので、人間を生成すると以下のような画像を出力することができます。
Refiner を使用する際はイラスト系よりもフォトリアル系のデータセットを持つモデルを使用するのが現時点ではベターであると言われています。

(9) Width・Height (画像サイズ)
こちらは生成する画像のサイズ(高さと幅)を指定します。
SDXLでは、標準の画像出力が1024 x 1024となっておりますので、出力解像度は合計 1024 × 1024 = 1,048,576 ピクセル程度が良いとされています。
つまり、YouTube のサムネイル(1280 × 720)を例に出すと以下のようになります。
YouTubeのサムネイル画像の推奨サイズ
サイズ:1280 × 720
比率:16:9
ピクセル数:921,600SDXL で画像生成する場合のサイズ
サイズ:1364 × 768
比率:15.9:9
ピクセル数:1,047,552
このようなピクセルサイズの計算方法は色々ありますが、少々面倒な計算になるので chatGPT で算出しました。同じような方法でサイズを指定すると、SDXL で最も良い生成結果が得られやすくなります。
SDXL の推奨サイズにはいくつかのチートシートがありますが、以下によく使うアスペクト比をまとめました。
1:1, 1024, 1024 # 1:1 Square(正方形)
2:3, 836, 1254 # 2:3 Landscape(景色)
3:4, 888, 1184 # 3:4 Photo(写真)
9:16, 768, 1364 # 9:16 thumbnail(サムネイル)
こちら比率や解像度を限りなく変更せずに済むように計算しているので、おそらく現在出回っているチートシートの中でも最も正確かと思われます。
また、推奨されているのはあくまでもこの指定サイズで生成される画像のピクセル数になりますので、これらは縦横入れ替え可能です。
こちらのチートシートは『sd-webui-ar』という拡張機能の resolutions.txt というファイルにそのまま貼り付けておくと、以下のようにサイズの変更がボタン一つで行えるので大変便利です。

Notebook 上からPython で書き換える場合などは、以下のように入力して実行することでファイルの書き換えを行うことができます。
f = open("<拡張機能のフォルダパス>/sd-webui-ar/resolutions.txt", "w")
text = """1:1, 1024, 1024 # 1:1 Square(正方形)
3:4, 886, 1182 # 3:4 Photo(写真)
2:3, 836, 1254 # 2:3 Landscape(景色)
9:16, 768, 1364 # 9:16 thumbnail(サムネイル)"""
f.write(text)
f.close()
(10) Batch count (バッチカウント)
こちらは入力された設定で画像生成を行う回数です。
例えば、Batch count が 2 だとすると、1回目の生成が終わった直後にもう 1 枚画像生成を行います。Batch count を 100 にすると、100枚の画像を生成します。
(11) Batch size (バッチサイズ)
こちらは入力された設定で画像生成を並列して行う数です。Batch size が 2 なら 2 枚の画像を同時に生成し、Batch size が 4 なら 4 枚の画像を同時に生成します。
並列処理で同時生成するため Batch count と比べると早く生成できますが、VRAM の容量をその分消費します。(グラフィックボードの性能によっては遅くなる場合もあります。)そのため、基本的には 2~4 に設定しておくと良いです。
また『Batch count:3、Batch size:2』 のように指定すると、『2枚の画像を同時に生成するという作業を3回繰り返す』ので、2 × 3 = 6枚の画像を生成できます。Batch count × Batch size の合計が最終的な生成枚数になると考えてください。
(12) CFG Scale (CFGスケール)
CFGスケールは直感的にはわかりにくいですが、入力したPromptにどのくらい従わせるかといった概念です。数字が大きいほどプロンプトの再現度が高くなります。
一般的に、低スケールだと柔らかく抽象的な絵柄の画像が生成され、高スケールにするほどより詳細かつより厳密にプロンプトを再現しようとします。基本的には『7』に設定する場合が多いです。
▫ CFGスケールごとの違い
実際に、CFGスケールごとによって生成される画像にどのような違いが生まれるかを見ていきます。
モデルやプロンプト・その他の設定は下記を使用します。
Model: SDVN7-NijiStyleXL
Prompt: anime,realistic,sketch,1girl,lip,Sweater,order,Blue gradient background,Neon hair,Textured crop,Canadian,(masterpiece,best quality,niji style)
Negative prompt: (worst quality, low quality,realistic,illustration, 3d, 2d, painting, cartoons, sketch),(MajicNegative_V2_0.8),verybadimagenegative_v1.3
Sampler: Euler a
Steps: 40
Seed: 2427071359
CFG scale: 1~15 (9~10 が推奨設定)
Size: 896 x 1280
以下の画像は、CFGスケールのみを変えて生成した結果の比較になります。結果からも分かる通り、CFGスケール低いほど柔らかく、高いほどディティールや『セーター、グラデーション、ネオン』といったプロンプトの命令を再現しています。

▫ CFGスケールの推奨値
CFGスケールはの値は学習モデルごとに推奨値がアナウンスされている場合が多いです。そのため、CFGスケールを指定する場合は使用モデルのダウンロードぺージを確認することをおすすめします。
以下は、今回使用した『SDVN7-NijiStyleXL』というモデルの詳細ページになりますが、こちらのモデルではCFGスケールを『9〜10』に設定することを推奨していますので、先程の比較画像でもその前後の値での生成結果が最も良くなっています。
(13) Seed
Seedとは、生成したイラストのランダム性を制御するためのパラメータです。機械学習では乱数を作成するときの最初の設定値をシード(種)値と言い、再現性やランダム性を考えた場合に重要な値として用います。
つまり、Seed値は生成画像ごとに割り当てられている固有の番号で、同じSeed値を指定すると同じイラストが生成されます。反対にSeed値を変えると、イラストの内容や絵柄が変わります。
また、プロンプトが多少変わっても、同じSeed値であれば似たイラストになります。以下はSeed値を『3694930446』に固定し、プロンプトを『expressionless, smile, angry, sad 』に変更して画像を生成した際の例です。着ている洋服や顔などにさほど差がない事が分かります。

この性質を利用して、Seed値を指定することで「赤いリンゴ」と「赤くて甘いリンゴ」ではどう違うかなどといった、プロンプトの精度や効果を検証したり好みのイラストを再現したりすることができるわけです。
また『好みの画像が生成できたが少し変えたい』といった時などに、Seed値を変更することで微調整をすることもできます。
Seed値の指定は以下の画像のように行なえます。
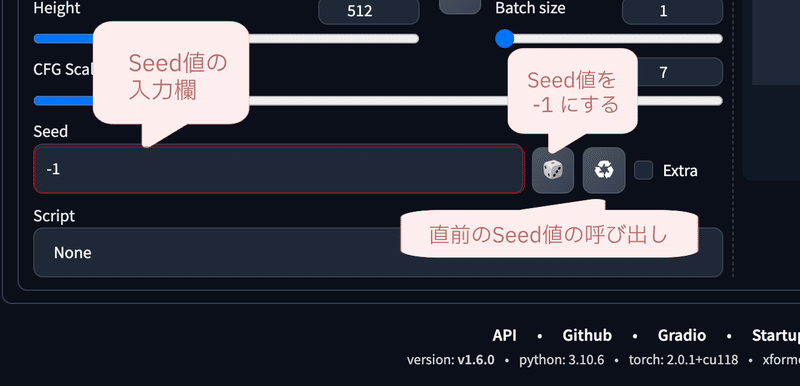
Seedの初期値は画像のように『-1』となっています。『-1』の場合は、ランダムな数値を画像生成の度に割り振ります。
この状態で、Batch count や Batch size 生成枚数を指定する場合でも全て違う画像が出力されます。
ちなみに、🎲 マークを押下すると、Seed値に『-1』を設定し、♻️ マークを押下すると、Seed値に『最後に生成しが画像のSeed値』を設定します。
『Extra』というチェックボックスでは、Seedのオプションを表示することができますので、生成画像を微調整したいときなどに非常に便利です。
チェックボックスにチェクをいれると、以下の画面が表示されます。

ここでは、以下の画像とパラメーターをもとに、Extraタブのそれぞれのパラメーターについて説明します。

Variation seed:
こちらは『Seed』で設定されている値に対するSeed値のような雰囲気の値になります。後述するVariation strengthと組み合わせて使用することが多く、Seed値を用いて生成した画像とVariation seedの値を用いて生成した画像をミックスさせることができます。
Variation seedは初期値では『-1』が設定されており、『-1』の場合はランダムな値を自動で設定します。
Variation strength:
Variation seedで設定したSeed値の画像にどれだけ近づけるかを決めるパラメーターになります。Variation seedと合わせて調整することで、ほんの少しだけ人物やキャラクターの特徴を変化させることができます。
このパラメーターの値が小さいほど元画像に似た画像を生成できるので、微修正する場合は『0.1』に設定することが多いです。詳細は後述します。
Resize seed from width,Resize seed from height:
Stable Diffusion WebUI では、画像生成後に同じ画像を異なる画像サイズで生成すると全く異なる画像が出力されますが、Resize seed from width,Resize seed from height に元画像と同じサイズを使うと構図をほぼ同じに保ちながら、画像の比率を変更できます。こちらも詳細は後述します。
▫ Seed値で生成画像を微調整する
先程、Variation seed を用いると Seed 値によって生成された画像とVariation seed で生成された画像をミックスさせるような働きをし、Variation strength を調節することによって、Seed 値で生成した画像と Variation seed で生成した画像のどちらに近づけるかをコントロールすることができると説明をしました。
ここでは、実際に Variation seed と Variation strength を使用して生成画像を微調整する例をご紹介します。
以下はSeed値を3694930446、Variation seedの値を -1 (ランダム) に設定し、プロントの『expressionless』を『smile, angry, sad』に変えた場合の比較画像です。また、Variation strengthを 0~0.7 に調整してプロンプトを調整し、その変化を表しています。

このように、プロンプトには髪の毛の長さの情報は入れていないのに対し、Variation strength が0の場合は『short hair』となり、 0.7 に近づくにつれて『long hair』になり体の向きまで変わっている事がわかります。
これは、 Variation seed の値を使って生成された画像な左向きでロングヘアーの画像であり、Variation strength でその画像にどのくらい近づけるかを調整した結果ということになります。
よって、Variation seedを画像生成時のSeedと同じものに設定するとVariation strength による違いはなくなります。
以下は、実際にSeed値を『3694930446』、Variation seedの値を『12345, 3694930446』に設定し、Variation strengthを調整した際の比較画像になります。12345 のときは変化が見られますが、3694930446 のときは変化が無いことがわかります。

ちなみに、上述した通り Variation strength は 『0.1』に設定して微妙な変化をつけることが多いです。
以下はSeed値を『3694930446』に設定して、Variation seedの値を『1, 12345, 3694930445, 3694930446』に設定し、Variation strength を『0.1』プロンプトを『expressionless, smile, angry, sad』に調整した比較画像になります。Variation seed とプロンプトを変化させることで生成画像の微調整ができることがわかります。

▫ Seed値で生成画像をリサイズする
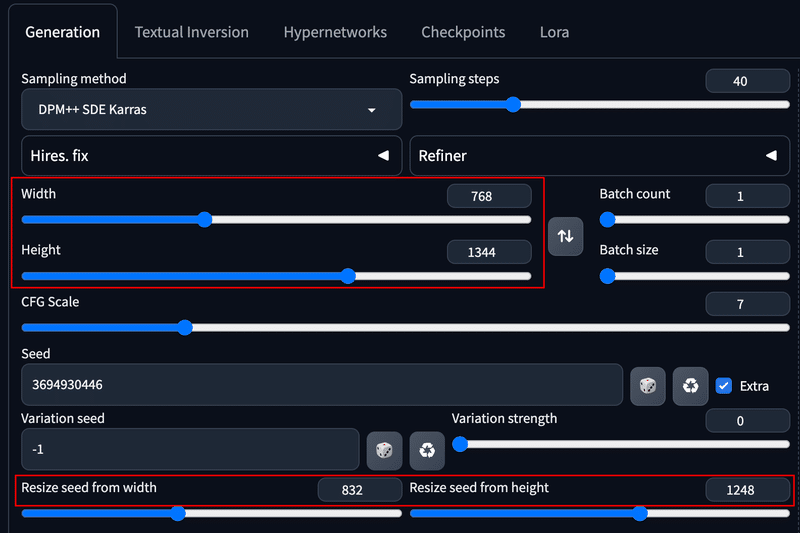
Resize seed from width,Resize seed from height を使用すると、構図を保ちながら生成画像のリサイズを行うことができます。
以下の赤枠内の設定を変更し生成を行うことでリサイズすることができますが、注意点として Resize seed from width,Resize seed from height に元画像の画像サイズを指定する必要があります。そして、Width, Height にリサイズしたい大きさを入力して画像生成を実行します。
リサイズの方法は、生成画像を指定サイズに合うように切り抜く形になります。
以下は、生成画像の指定サイズを 1:1, 3:2, 3:4, 9:16 といったように大きさを変化させた場合の比較画像になります。若干の変化はありますが、構図を保ちつつ生成されていることがわかります。

(14) Script
Scriptでは、異なるプロンプトやモデル、サンプラーやその他の設定ごとで画像生成を行い、その比較画像(マトリクス表)を作成することができます。
つまり、それぞれの比較を行うことで、プロンプトやその他のパラメーターがどのように作用しているのかを調べることができ、効率的な画像の生成テストをすることができます。
目的とする画像を作成するにあたって、使用するモデルや様々なバリエーションのプロプトを試してみたい時などに大変便利です。
以下のScript のタブを開くと、使用できる機能が表示されます。

デフォルトでは以下の機能が利用できます。
Prompt matrix (プロンプトマトリックス):
プロンプトのパターンを総当りて出力します。Prompts from file of textbox:
テキストボックスやテキストファイルのプロンプトを、1 行ごとに分けて画像生成を行います。X/Y/Z plot(X/Y/Zプロット):
横軸・縦軸にパラメーターと値を設定し、比較表を作成します。
Script に関しては、以下の記事で詳しく解説しています。
追加学習モデルついて
こちらでは、先ほど解説した Generationタブ以外の項目の説明を行っていきます。
『Textual inversion, Hypernetworks, LoRA』 といった項目がありますが、こちらは追加学習モデルの設定を行うタブになります。
追加学習モデルとは、学習モデルのデータセットに加えて後続的に追加するデータセットのことで、学習モデルのネットワークに新しい層やパラメータを 追加したり、既存の層やパラメーターを調整したりする事によって、画像の生成結果を微調整することができます。
つまり、この追加学習モデル を使用することによって、画像の品質を改善したり、 特定のキャラクターの洋服やポーズや顔といった特徴を生成画像に反映することができます。
なお、 繰り返しになりますが、Textual inversion, Hypernetworks, LoRA といった、各モデルの保存先や探し方については、学習モデルやVAE と 同様に『● 学習モデルの探し方とライセンス > 各モデルのダウンロード先』 で 詳細に解説を行っておりますので、このチャプターでの説明は省略いたします。
具体的には、以下の画像の赤枠部分に関して解説を行っていきます。
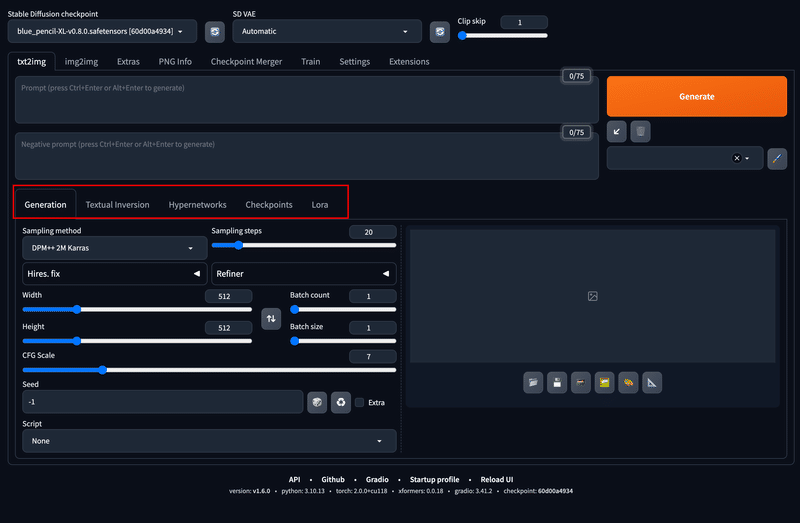
Textual inversion (Embeddings)
Textual inversion (Embeddings) は、テキストエンコーダの埋め込み空間において、新しい単語や概念を学習するモデルです。
テキストプロンプトと対応する画像のペアを入力することで、新しい単語に対応する埋め込みベクトルを学習しています。
つまりは、プロンプトやネガティブプロンプトの傾向をまとめた学習ファイルのようなものになります。
特徴としては、比較的容易に作成することが可能で、 モデルファイルの容量も数KBと、大変軽いといったことが挙げられます。
Stable Diffusion WebUI では、以下のように『Textual inversion』のタブを開くことによって、ダウンロードした Embeddings のファイルを開くことができます。 こちらのモデルカードをタップすると『unaestheticXL_Sky3.1』のように、プロンプトの末尾にEmbeddingsのファイル名が入力されます。
Embeddings は、主にネガティブプロンプトの傾向をまとめたものが多く、ファイル名やトリガーワードをプロンプトやネガティブプロンプトに入力するだけで簡単に使用する事ができます。
例えば、『unaestheticXL_Sky3.1』というモデルでは、ネガティブプロンプトにファイル名を入力するだけで、画像をある程度まで鮮明かつ詳細に表示し、エラーをある程度まで修復することができます。
使用する場合、『unaestheticXL_Sky3.1』とネガティブプロンプトに記述し、生成ボタンを押下します。また、このときにプロンプトの重み付けも設定することで、Embeddings の効き目を調整することもできます。
以下はその例の比較画像です。

また、『badhandv4,EasyNegative』 のようにプロンプトに記載することで、 以下の例のように他のEmbeddings と組み合わせることもできます。

Hypernetworks
Hypernetworksは、U-Netのクロスアテンション層に新しい層を追加することで、画像の生成結果のスタイルや品質を調整するモデルです。
数十枚ほどの画像とその画像を表す単語やタグのペアを入力することで、新しい層のパラメータを学習しますので、数MB~数十MB ほどの容量があります。
Hypernetworks では、アートスタイルを適用させたり、生成結果の細かさや鮮明さを向上させ たりといったものが多く、主にポジティブプロンプトに作用します。
こちらは、『 <hypernetworks:Hypernetworksのファイル名:1> 』のように、『 <> 』とモデルに対する重み『 :1 』をプロンプトに入力することで適用することができます。
ちなみに、この手法は学習に手間がかかる上に現在はあまり流行っておらず、SDXL で使用できるものに関しては CivitAI などで探してみてもあまり 検索結果にヒットしないといった状況です。
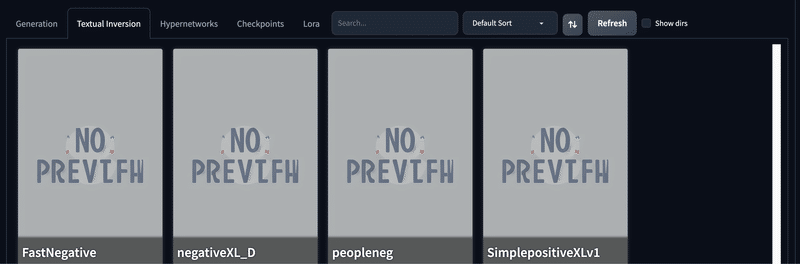
Checkpoints
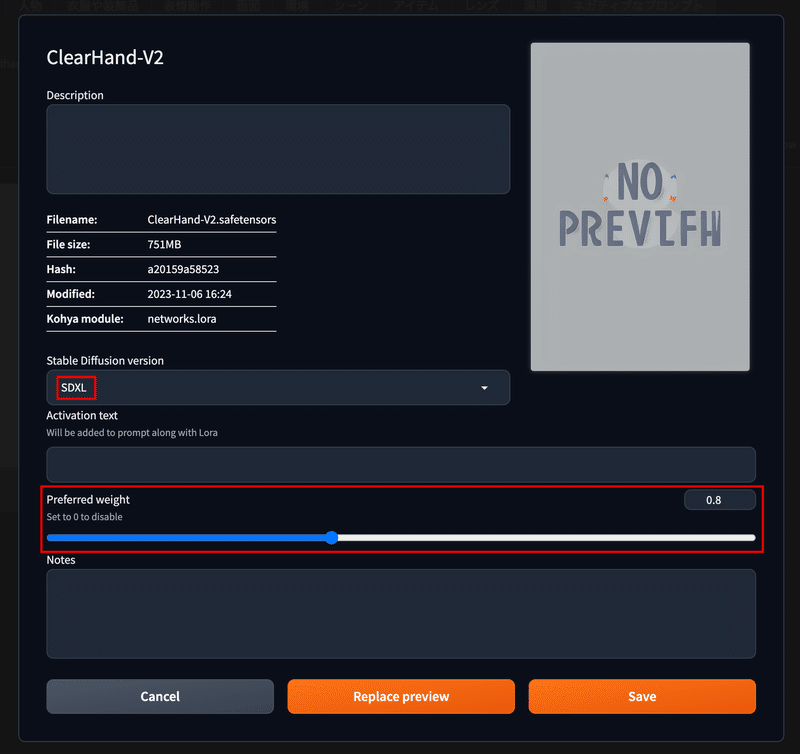
こちらは、先ほども説明した学習モデルのファイルを設定するタブになります。
Checkpoints のタブを開くと、以下のようにカード形式で学習モデルの一覧を見る事ができ、カードをクリックすると学習モデルが『Stable Diffusion checkpoint』の部分にロードされます。
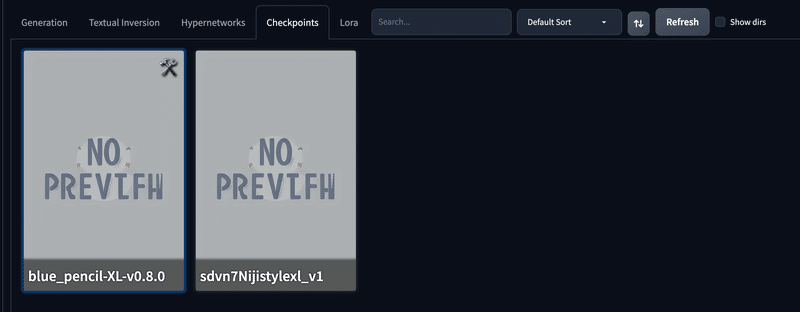
また、学習モデルのカードの 🛠️ マークを押下すると、以下のように学習モデルの情報を見たりメモをすることができます。
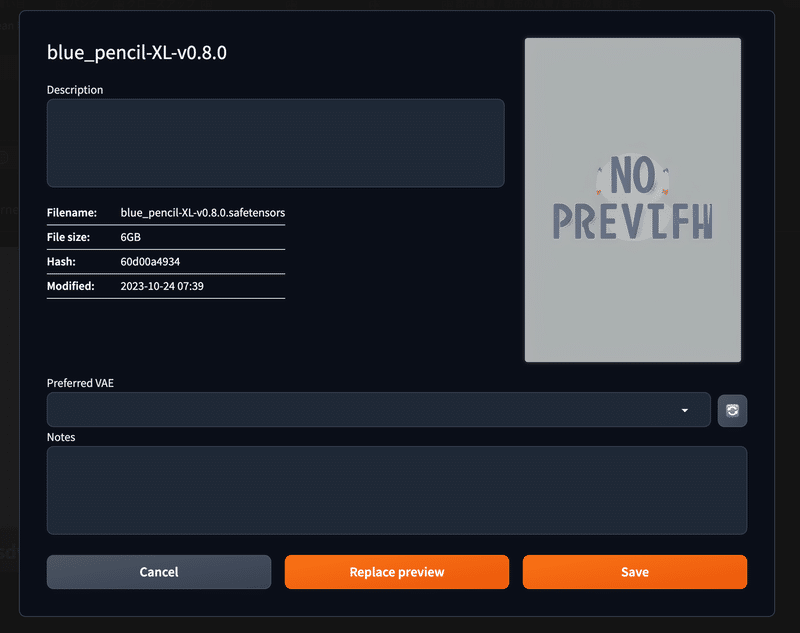
この画面でPreferred VAE を押下すると、学習モデルごとに使用するVAEを選択することができます。
VAEに関しては学習モデル毎に推奨されるものがありますので、よく使用するものに関してはこちらで設定しておくと大変便利です。
LoRA
LoRA はLow-Rank Adaptationの略で、U-Netのクロスアテンション層の重みを調整することで、画像の生成結果のスタイルや品質を調整するモデルです。
数十枚ほどの画像とその画像を表す単語やタグのペアを入力することで、重みの値を学習しますので Hypernetworksと少し似ていますが、生成結果の品質や一貫性がより高いとされています。
LoRA は、数十MBから、数百MBほどの小さな容量で、 『 <lora:LoRAのファイル名:0.8> 』のように、『 <> 』とモデルに対する重み『 :0.8 』などをプロンプトに入力することによって、特定のキャラクターの顔や服装といったものから、背景やアートスタイルなどといったものまで、 学習させた画像の特徴を 比較的正確に生成結果に反映させることができます。
つまり、特定のキャラクターやイメージをある程度固定して、画像生成を行いたい時などに非常に有効な手法になります。
またLoRAの進化版のようなもので、LyCORISと言うものがありますが、Stable Diffusion WebUI では、 両者とも同じようにして扱うことができます。
LoRA のタブを開くと、以下のように、LoRA や LyCORIS のモデルカードが表示されます。 なお、LoRAも上記と同様に、こちらのモデルカードをクリックすると『<lora:ClearHand-V2:1>』といったように、ローラのファイル名と重みが プロンプトの末尾に入力されます。この時、重みに関しては1がデフォルトで選択されます。

なお、こちらもチェックポイントの時と同じようにして、モデルカードの詳細を以下のように表示することができます。詳細欄では、LoRAが動作するStable Diffusion のバージョンを確認したり、重み付けの初期値を設定することができます。
その他の便利なボタン
Stable Diffusion WebUI の画面には、以下のようなボタンも備わっています。ここではこれらのボタンに関して1つ1つ説明を行っていきます。

Generateボタンのオプション
Generate ボタンはその名の通り画像生成を実行するボタンになりますが、実は細かいオプションがありますのでそちらを解説します。
▫ ⌘(Control)+ Enter
こちらは Generate ボタンのショートカットキーです。
このキーを押すと、わざわざ Generate ボタンにカーソルを合わせてボタンをクリックしなくとも画像生成を実行することができます。
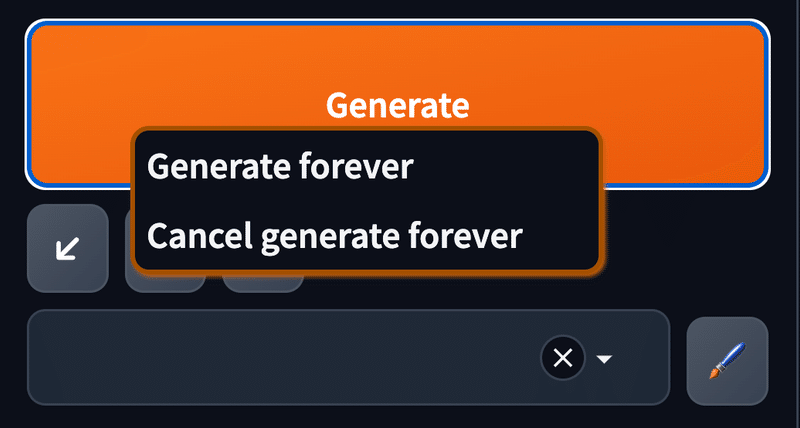
▫ Generate forever ・ Cancel generate forever
Generateボタン を右クリックすると『Generate forever ボタン / Cancel generate forever ボタン』が表示されます。
Generate forever ボタン
画像生成を永続的に実行するボタンです。
Generate forever ボタンを押下して実行中、プロンプトを変更すると次回の生成から反映して画像生成します。Cancel generate forever ボタン
Generate forever ボタンでの永続実行をキャンセルします。
Generate forever ボタンの注意点として、Seed が『-1』となっていることを必ず確認してから実行してください。Seed値が固定だと、永遠と同じ画像が出力されてしまいます。
↙️ ボタン, 🗑 ボタン
↙️ ボタンでは、1つ前に使用していた『Prompt、サイズ、Seed、サンプラー、CFGスケール』などといったの設定情報を呼び出し設定するためのものです。
Stable Diffusion で生成したデータは終了してもデータが保持されますので、起動後であってもこちらのボタンを押すと終了前のPromptなどの情報を再度読み込むことができます。
🗑ボタンでは、現在入力されているプロンプトとネガティブプロンプトの一括削除を行うことができます。
その他のステップ数やサンプラーなどはリセットされませんので、プロンプトを他のものに変更したい場合に便利です。
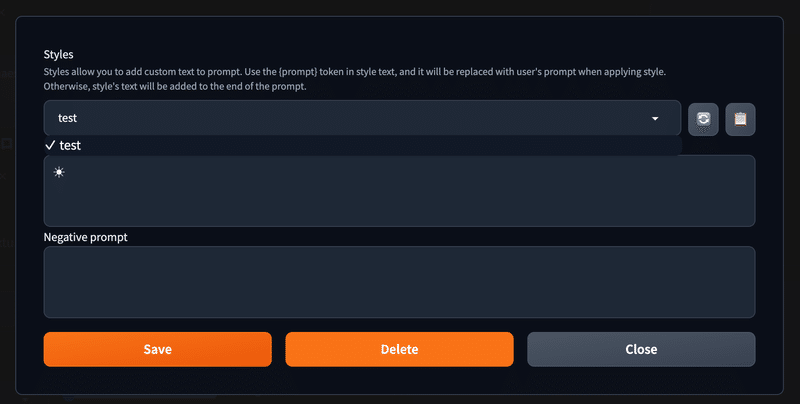
🖌️ ボタン
こちらのボタンでは、以下のようにスタイル名とプロンプトを入力して、スタイル保存することができます。以前は『スタイル(Styles)』と呼ばれていました。
保存したスタイルは、プルダウンから選択して 📋 ボタンを押すことによって、現在入力しているプロンプトの末尾に追加されます。

スタイル名を記載した場合、以下のように『Save』と『Delete』ボタンが表示されます。
これらは、名前の通り『Save』とすると現在のスタイルが保存され、『Delete』とすると選択中のスタイルが削除されます。
📂 ボタン
📂 ボタンでは、 生成した画像の保存されてあるフォルダを開く事ができます。 こちらは、Stable Diffusion WebUI のインストールされているハードウェアのAPIを使用して動作しますので、クラウド環境では機能しません。
💾 ボタン, 🗃️ ボタン
💾 ボタンでは、 生成した画像の保存先リンクを作成し、自身のPCのダウンロードフォルダにブラウザ経由でダウンロード することができます。
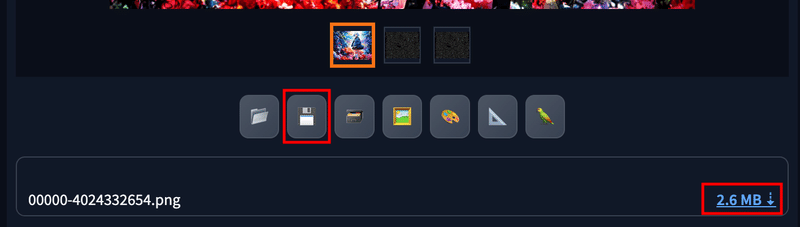
🗃️ ボタンでは、 同じようにして、生成した画像の保存先リンクを作成しますが、この時に画像zipで圧縮してリンクを作成することができます。

🖼️ ボタン, 🎨️ ボタン, 📐 ボタン
🖼️ ボタンでは、 生成した画像と、生成に使用したステップやプロンプト、サンプラーなどの設定情報を、img2img に転送できます。
🎨️ ボタンでは、 生成した画像と、生成に使用したステップやプロンプト、サンプラーなどの設定情報を、img2img の inpaint に転送できます。
📐 ボタンでは、 生成した画像を、Extras タブに転送できます。
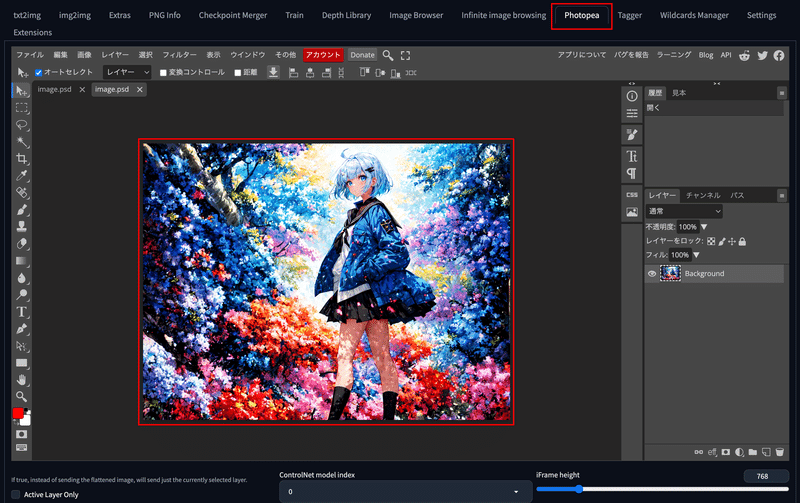
🦜 ボタン
🦜 ボタンでは、Photopea という拡張機能がインストールされている場合に表示され、生成画像を Photopea のタブに転送することができます。
このように、 Stable Diffusion WebUI には、拡張機能をインストールしたことによって、自動的に追加されることもあります。
Photopea では、以下のようにPhotoshopのような編集画面で生成した画像を直接編集することができます。 これにより、SNSに投稿する画像にIDなどの透かしを入れたりなどということや、 レタッチや編集をして、再び Stable Diffusion WebUI の img2img などに画像を転送することができます。
● image2imageとは?
image2image に関しては、以下の記事で詳しく解説しています。
● Extras
Extras に関しては、以下の記事で詳しく解説しています。
● PNG info
PNG info は 画像のメタデータを表示する機能です。生成した情報を確認するのに大変便利な機能ですので、このチャプターで詳しく解説していきます。
生成した画像のプロンプトやSeed値を確認する
PNG info では、以下のように『PNG Info』を開き画像をアップロードすると『parameters』という画像のメタデータが表示され、過去に Stable Diffusion WebUI で生成した画像のプロンプトやSeed値を確認できます。

Stable Diffusion WebUI で生成された画像には、上記のような生成時に使用した設定がメタデータとして保存されますので、仮に他の人が生成した画像でも『PNG info』を利用すればこのようにプロンプトや設定などを知ることができます。
過去の画像と同じ画像を生成する
PNG Info では表示したパラメーターは、以下のボタンを押すことでそのまま『txt2img や img2img』に送ることが可能です。

試しに txt2img に画像を送信すると、以下のように全く同じ設定がパラメーターに入ります。
この状態で 『Generate』ボタンを押して生成すると、全く同じ画像を生成することができます。

PNG Info の注意点
PNG Info の注意点としては、PhotoshopやPhotopea 、Gimpなどの外部編集ソフトで編集したものはメタデータが上書きされてしまうことが挙げられます。
この場合、PNG Info に画像をアップロードしてもメタデータが表示されないため、注意が必要です。
また、PNG Info で txt2img や img2img にパラメーターを送ると、各パラメーターに生成時と同じ値が設定されますが、Checkpoint(学習モデル)や Refiner、Script のような、自動で設定されないパラメーターも存在します。 そのため、そのようなパラメーターに関しては自分で都度選択する必要があります。
● Settings
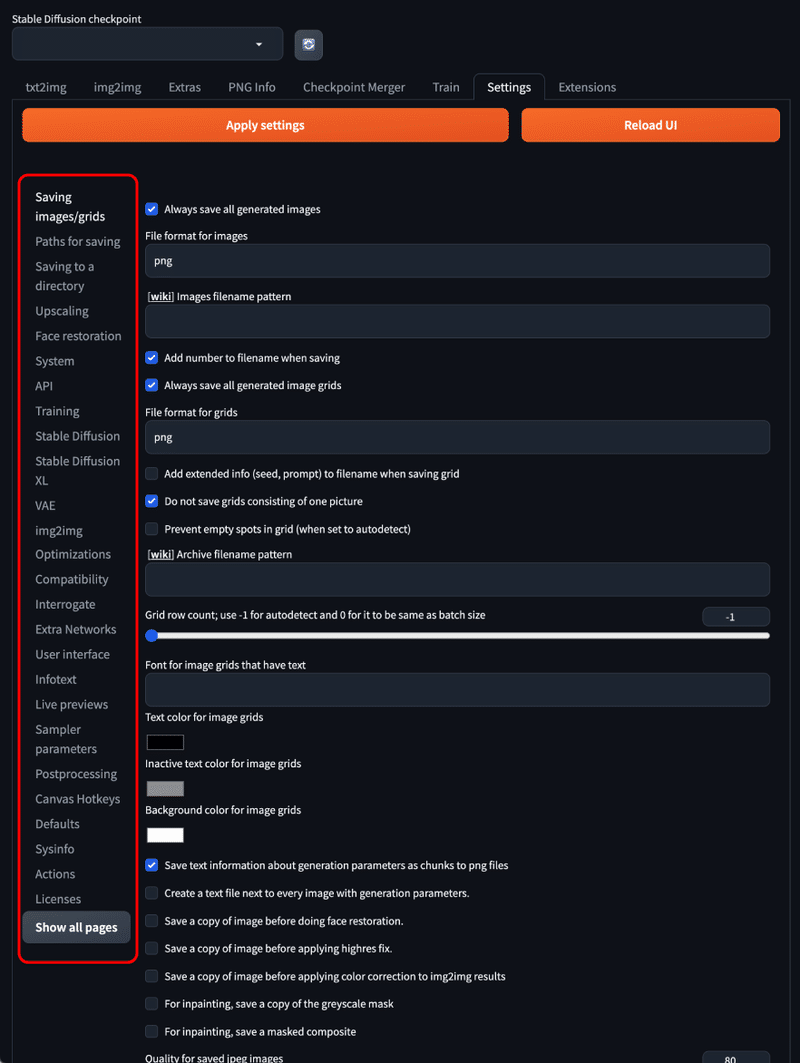
Settings はStable Diffusion WebUI の設定を行う項目です。以下のように、画像の赤枠内の項目の数だけ設定があります。
こちらは好みによって設定を変更すれよいですが、おすすめの設定をいくつかご紹介します。
生成される画像のファイル名をカスタマイズする
Stable Diffusion WebUI では、画像生成の際に保存されるファイル名は『00001-1234567810.png』のように『連番-Seed値.png』というファイル名で保存されます。
こちらを『連番-モデル名‐Seed値.png』のような、自分の好きなファイル名の形式に変更することができます。
設定するには、以下のように設定の中から『Saving images/grids』を選択し『 [wiki] Images filename pattern』と記載のある箇所を編集します。

設定できるパラメーターは [wiki] のリンクをクリックすると閲覧できます。かなり多くの種類がありますが、本稿では一部を抜粋して紹介します。
[seed]:Seed値
[steps]:ステップ数
[cfg]:CFGスケール値
[sampler]:サンプリングアルゴリズム
[model_name]:学習モデル名
[date]:生成した日付 (2023-12-31)
[datetime]:生成した日付時刻 (20231231123400:年月日時分秒)
[prompt]:プロンプト(スペースは _ に変換される)
[prompt_spaces]:プロンプト (スペースはそのまま残される)
[clip_skip]:Clip skip値
設定の仕方は、以下の画像のようにモデル名とシード値なら『 [model_name]_[seed] 』と指定します。

この場合、仮にモデル名が『sd_xl_base_1.0.safetensors』であるならば、その場合の実際に出力される生成画像ファイルの名前は『00001-sd_xl_base_1.0_1234567810.png』といったように『連番-モデル名_Seed値.png』と表記されます。
設定した変更を反映するには、以下のように『Apply settings → Reload UI』と順にクリックします。
これで『設定を適用 → Stable Diffusion WebUI をリロード』となり、再起動後に設定が適用されます。
画像保存先のサブフォルダをカスタマイズする
Stable Diffusion WebUI では、画像生成の際に保存されるフォルダはデフォルトでは
・outputs/txt2img-images/日付/ファイル名.png
・outputs/img2img-images/日付/ファイル名.png
のように、『日付別』のサブフォルダに保存されます。
こちらを、先程のファイル名の命名パターン変更と同様に、『日付』部分のサブフォルダの名前を『モデル名_日付』のような自分の好きな形式に変更することができます。
設定するには、以下のように設定の中から『Saving to a directory』を選択し『 [wiki] Directory name pattern』と記載のある箇所を編集します。
本稿では、例として『[model_name]_[date]』とします。
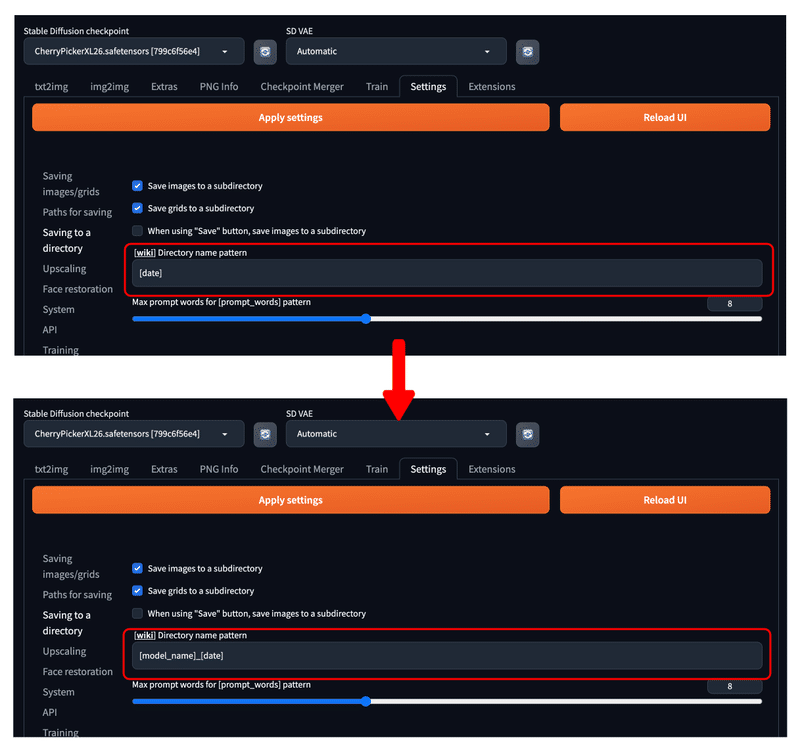
このようにして、生成画像の保存先を
・outputs/txt2img-images/モデル名_日付/ファイル名.png
・outputs/img2img-images/モデル名_日付/ファイル名.png
のようにすることができます。
こちらも設定後、Stable Diffusion WebUI に反映するために『Apply settings → Reload UI』と順にクリックしてください。
ちなみに、こちらの命名規則もファイル名と同様なので [wiki] のリンクからアクセス可能です。URL は下記になります。
Clip Skip ・ VAE を表示する
こちらは先ほど解説した Clip skip を表示する設定になります。
設定するには、以下のように設定の中から『User interface』を選択し『 [info] Quicksettings list』と記載のある箇所を編集します。
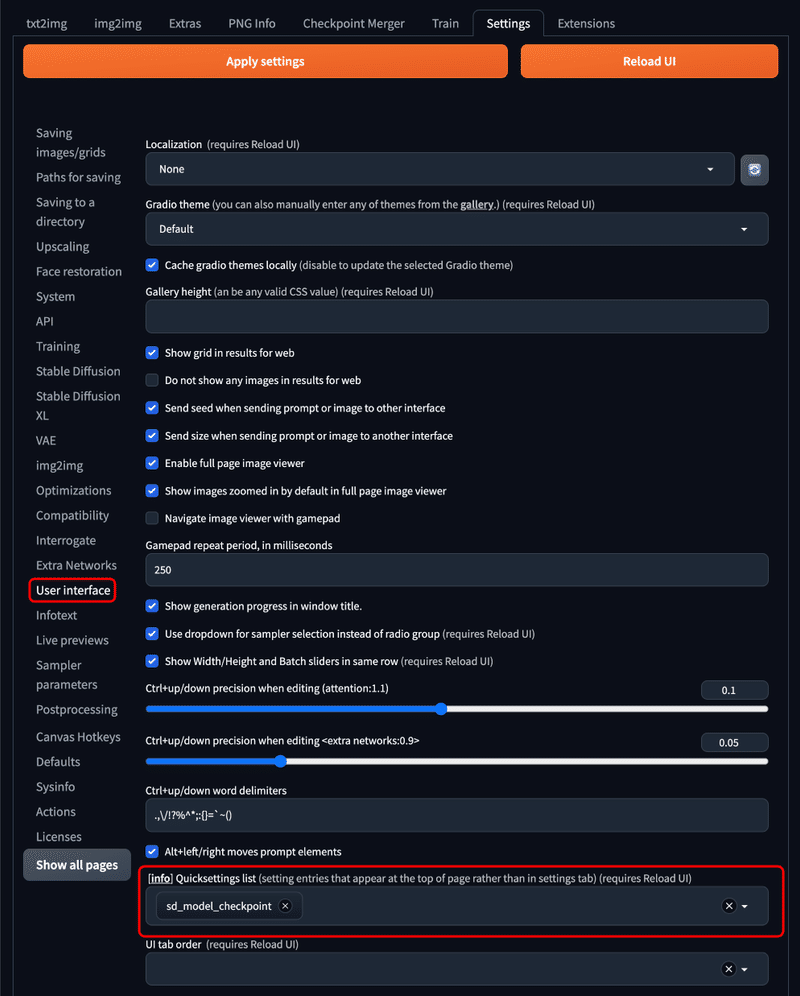
この箇所に『CLIP_stop_at_last_layers』と入力して、Enterを押します。
以下の画像の様になるはずです。
ちなみに、VAEも表示させたければ『sd_vae』と入力するとVAEも表示されます。
設定の適用は上記と同様、『Apply settings → Reload UI』と順にクリックして行います。
すると、以下のように Clip skip がクイック設定で表示されていることがわかります。
他のパラメーターは以下のように [info] をクリックすると確認できます。
Stable Diffusion WebUI の日本語化
Stable Diffusion WebUI は全て英語表記になるので、英語に苦手意識がある方だと少々使いづらいかもしれません。
幸い、Stable Diffusion WebUI は有志の方が様々な言語での翻訳を行ってくださっており、後述する『Extensions』タブと『Settings』を用いることで日本語化する事ができます。
しかし、日本語化にはデメリットも存在するので、先に日本語化する注意点を記載します。
▫ 日本語化する場合の注意点
Stable Diffusion WebUI を日本化する場合の注意点としては、英語表記にするとところどころ翻訳があやふやな部分があり、いまいち何を表現しているのか分からなくなる事が挙げられます。
一例として、後述する CivitAI や Hugging Face などのモデル説明欄に記載のある推奨設定項目の場所がわからなくなったり、Stable Diffusion WebUI でエラーが起きたときなどのトラブルに対応しづらくなることがあります。
また、生成AI はネットリソースが英語表記の場合が多く、英語表記のまま使用する方がメリットが大きいので日本語化を行わないユーザーも多いです。
本稿でも英語表記のまま使用しますが、必要な方は以下の手順で日本語化してください。
▫ 日本語化する手順
まずは日本語化をする機能のインストールを行います。
以下のように『Extensions』タブ → 『Available』と開きます。
『Load from:』の横に『https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.json』の記載があることを確認してください。
その後、『localization』のチェックを外し『Load from: 』を押下します。
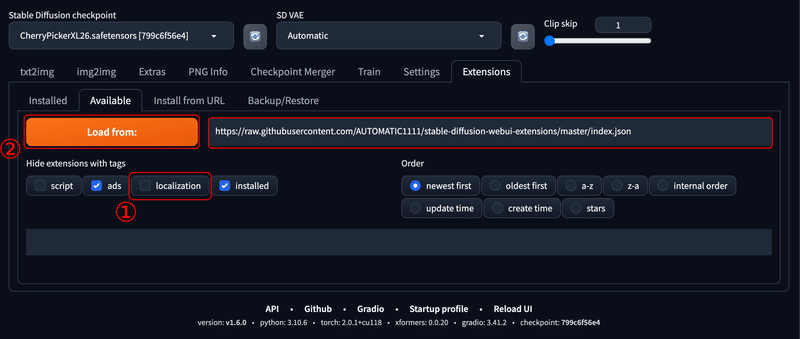
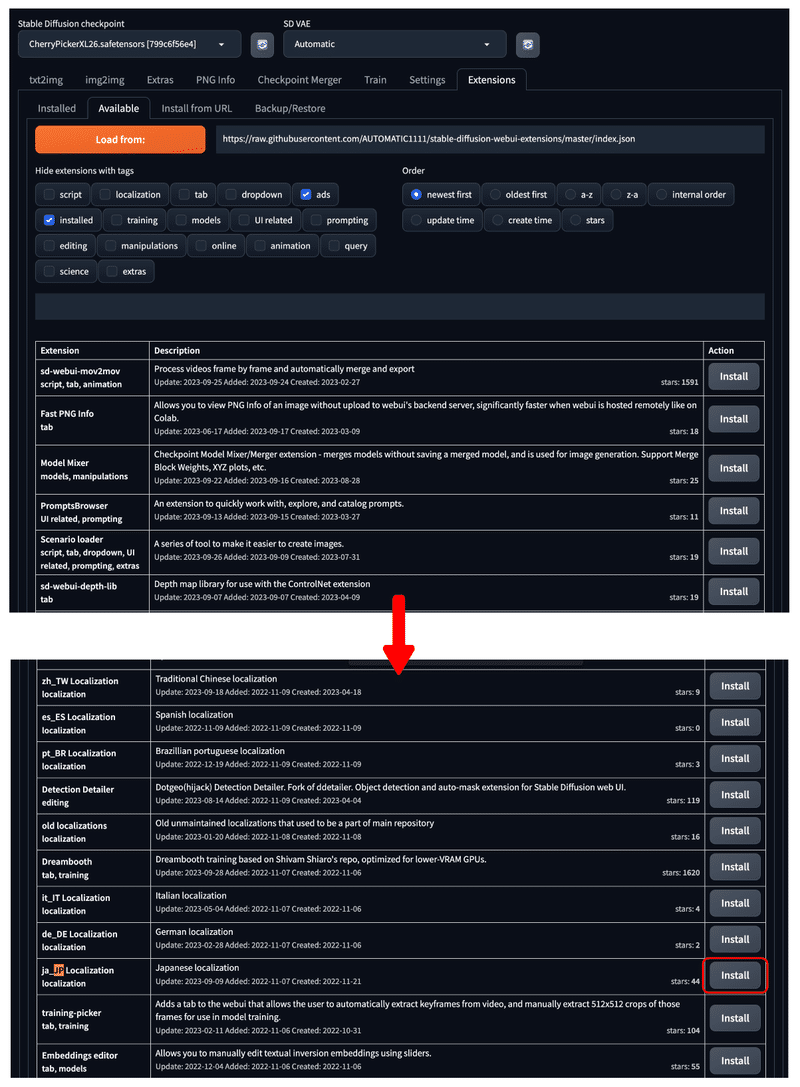
以下のようにインストールできる機能が大量に表示されますので、『ctrl(⌘) + F 』などを押して『jp』などと検索します。
『ja_JP Localization』と出てくるので、その横の『install』をクリックしてください。
続いて『Settings』の『User interface』から、『Localization』の横の 🔄 をクリックして、プルダウンを開いてください。
🔄 をクリックすると、先程インストールした日本語化機能に設定している値を使用できるようになります。
以下のように、『ja_JP』を選択します。
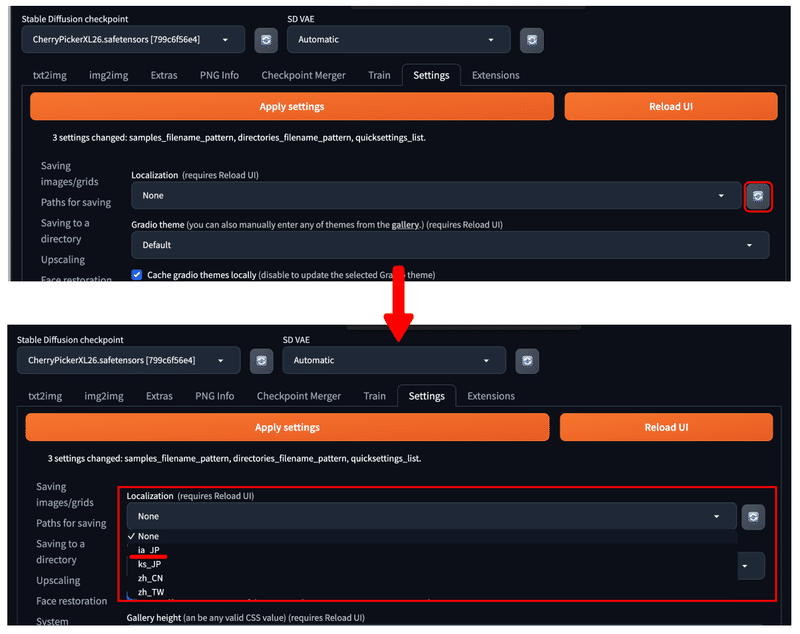
『Apply settings → Reload UI』として設定を反映させると、以下のように日本語表記に切り替わります。

以上が Stable Diffusion WebUI の日本語化の説明になります。
● Extensions
Extensions に関しては、以下の記事で詳しく解説しています。
● ControlNet
ControlNetとは?
画像生成AIには、色々なことができますが、その中でもより革命的な技術であるcontrolnetについて説明します。
ControlNetは、2023年2月にリリースされた比較的新しい技術で、Stable Diffusionの画像生成のランダム性をある程度コントロールできる拡張機能です。
今までにご紹介した画像生成方法は、プロンプトやseed値などで微調整して画像生成を行うものでした。この方法はプロンプトに指定の仕方によっては自由な構図のものを生成できる反面、非常にランダム要素が強いという特徴があります。
対して、このControlNet という拡張機能は『入力画像から棒人間や深度マップ・線画などを推定して画像生成に用いる』といった機能です。
また、ControlNetは、画像生成モデルの中間層に注入される別のネットワークでもあります。『画像を生成を行うの情報の条件付き側・画像を改善する無条件付き側』という場所にControlNetを注入する事によって、学習された条件から画像生成の方向性を変えることができるのです。
つまり、ControlNetは今までユーザーがランダムに生成していたものを、入力画像を用いてある程度コントロールして画像生成を行える非常に強力な機能であると言えます。
controlnetを使うと、以下のようなことができるようになります。
別の画像のポーズを真似する:controlnetを使うと、別の画像のポーズを自分の画像に適用できます。例えば、キャラクターのポーズを変えたり、人物のポーズを動物にしたりできます。
同じキャラの服装や表情を変える:controlnetを使うと、同じキャラクターでも服装や表情を変えることができます。例えば、キャラクターの服装を季節やシチュエーションに合わせたり、キャラクターの表情を感情や状況に合わせたりできます。
ポーズを自由に変える:controlnetを使うと、ポーズを自分で決めることができます。例えば、ポーズの角度や位置や大きさを調整したり、ポーズのパーツを組み合わせたりできます。
背景だけを入れ替える:controlnetを使うと、背景だけを別の画像に変えることができます。例えば、背景の場所や時間や雰囲気を変えたり、背景に合わせて光や影を調整したりできます。
他の画像から服装を借りる:controlnetを使うと、他の画像から服装だけをコピーして自分の画像に貼り付けることができます。例えば、他のキャラクターの服装やアイテムを自分のキャラクターに着せたり持たせたりできます。
同じキャラで別イラストを作る:controlnetを使うと、同じキャラクターでも別イラストを作ることができます。例えば、キャラクターの髪型や目の色や肌の色などを変えたり、キャラクターに別の特徴やアクセサリーなどを付け加えたりできます。
キャラを消す:controlnetを使うと、キャラクターだけを消して背景だけにすることができます。例えば、キャラクターが邪魔だったり気に入らなかったりする場合に消したり、背景だけで別のイラストに使ったりできます。
線画化する:controlnetを使うと、カラー画像から線画だけにすることができます。例えば、線画だけでイラストの雰囲気や構図を確認したり、線画だけで別の色塗りに挑戦したりできます。
線画に色塗ってもらう:controlnetを使うと、線画からカラー画像にすることができます。例えば、線画だけでは面倒な色塗りを画像生成AIに任せたり、線画に合わせて色味や明るさを調整したりできます。
手の形状を3Dモデルで描いてもらう:controlnetを使うと、手の形状を3Dモデルを参考にして描いてもらうことができます。例えば、手の形状が難しい場合に3Dモデルを使って手助けしてもらったり、手の形状を自分で決めたりできます。
ノイズ法
『● Stable Diffusionが画像を作るしくみ > Stable Diffusion の 画像生成の過程』で解説した、潜在的拡散モデルのしくみを使用して、ControlNet にノイズ画像を入れて生成する方法。




このようにControlnetを使用して様々なことができますが、実はこれをマルチで使うこともできます。これらが、Controlnetのもっとも革新的な点です。
ControlNet に関しては、以下の記事で詳しく解説しています。
● 学習モデルの探し方とライセンス
学習モデルの入手先は、現在は以下の2つが主流です。
CivitAI
Hugging Face
それぞれ詳しく説明していきます。
CivitAI
CivitAI は、画像生成AIのモデルを投稿できるウェブサイトです。一般の方がよく使っています。学習モデルだけでなく、「LoRA」や「Textual Invarsion」という画像生成AIの能力を高める機能も、このサイトで見つけることができるのが特徴です。
以下のように見やすいデザインで、実際に生成される画像を確認しながら探すことができます。

サイトは以下になります。
▫ モデルを探す方法
上部の検索窓から検索ができ、以下のファイルなどをダウンロードできます。
学習モデルファイル
LoRAの追加学習ファイル
Textual inversionの追加学習ファイル
Stable Diffusion WebUI用の拡張機能
ControlNetのキャラクターポーズ、深度マップ等
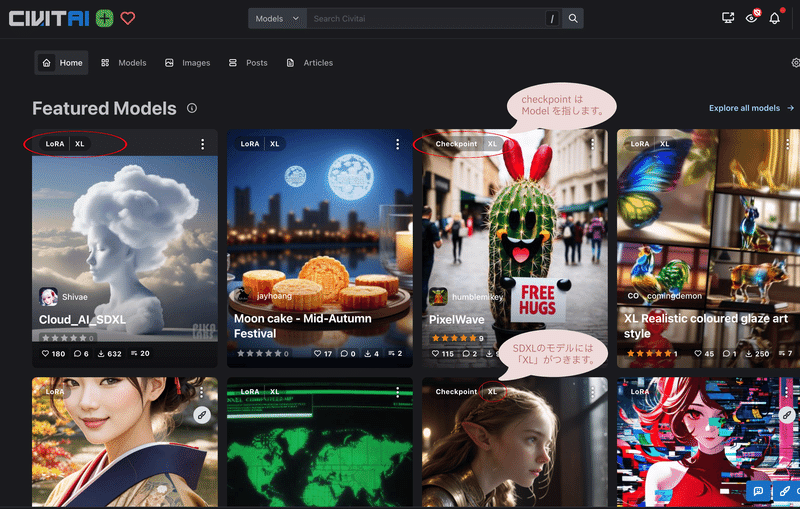
以下のように、モデルカードの左上に『Checkpoint』や『LoRA』のような、モデルファイルの種類が表示されています。
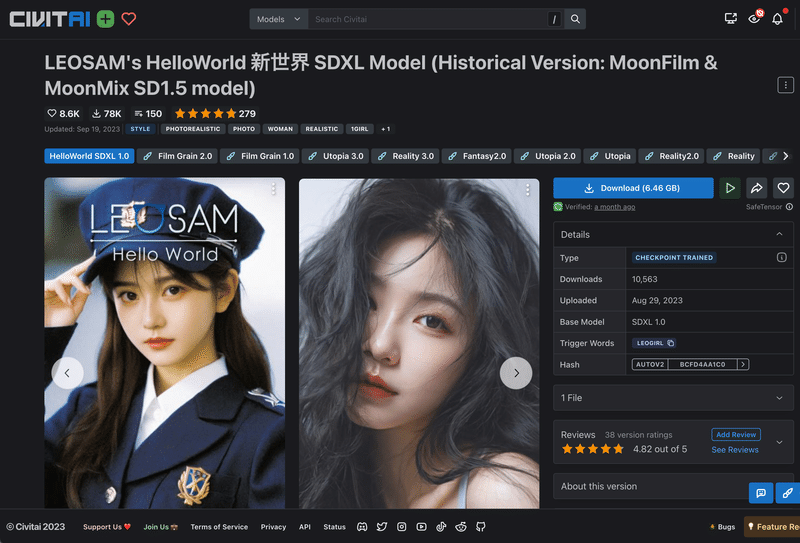
カードの画像をクリックすると、以下のようにモデルの詳細を確認できます。
詳細ページでは、次の項目などが確認できます。
モデルのバージョン
モデルのお気に入り数や評価
Type: CHECKPOINT TRAINED(カスタムモデル)
Downloads:ダウンロードされた数
Update:最終更新日
Base model:ベースにしたモデル
Trigger Words:モデルに付与されたタグ
下にスクロールすると、以下を確認できます。
License:ライセンス情報、利用規約
Show More:推奨されるプロンプトや設定などの説明文
Suggested Resources:推奨されるLoRAやTextual inversionなど
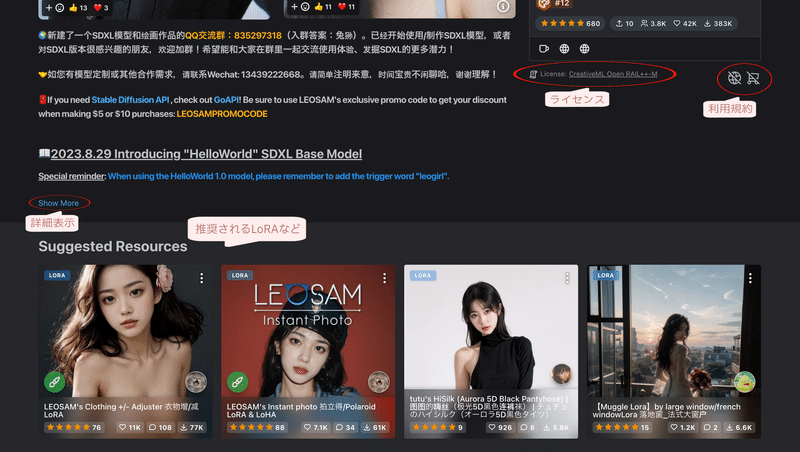
▫ モデルのライセンス
ライセンスとは、ソフトウェアやモデルなどを作った人と、それを使う人との間の契約のことです。 『無料で公開されているものでも、使用条件や利用規約を取り決めた範囲で使用を許可する』といったものになります。
このモデルに付与されている『CreativeML Open RAIL-M ライセンス』とは、Stable Diffusionやその派生モデルが採用しているライセンスの一種です。
このライセンスは、生成した画像を自由に使用・配布・販売することを許可していますが、同時に、悪用や法令違反などの禁止事項や責任の所在などを定めています。
詳しくは、以下のリンクを参照してください。
https://github.com/CompVis/stable-diffusion/blob/main/LICENSE
その他の取り決めに関しては、地球儀などのアイコンがある『利用規約』の部分をクリックすると以下のように『This model permits users to(このモデルがユーザーに許可すること)』が詳しく表示されます。

利用規約について解説すると、以下のようになります。
Use the model without crediting the creator
作者の名前やクレジットを明記せずにこのモデルを使用すること。これに❌がついている場合は、画像を公開する際に、作者の名前やクレジットを記載しなければなりません。Sell images they generate
生成した画像を販売すること。これに❌がついているモデルは、作った画像を売ることができません。Run on services that generate images for money
画像生成サービスでこのモデルを動かしてお金を稼ぐこと。または利益を得ること。これに❌がついているモデルは、生成サービスで使用してお金を稼ぐことはできません。また、無料で提供して広告収入を得るのも禁止されていると解釈できます。Run on Civitai
Civitaiやその連携サービスなどでこのモデルを使用して生成を実行すること。CivitAIはさまざまなサービスを通じてモデルやLoRAが利用可能ですが、これに❌がついているモデルは、その連携サービスなども実行することができません。Share merges using this model
このモデルと他のモデルをマージ(組み合わせた)したものを再配布(他人に配る)すること。これに❌がついているモデルは、派生物を再配布することはできません。Sell this model or merges using this model
このモデルや、このモデルとマージしたものを販売すること。これに❌がついているモデルは、派生物も含めて、モデルそのものを販売することはできません。Have different permissions when sharing merges
このモデルとマージしたものを、このモデルと異なる制約で公開すること。これに❌がついているモデルは、派生物に対してもこのモデルと同じ制約を全て引き継ぎ、遵守しなければなりません。制約を増やすことも減らすことも禁止されています。
※ 一般的な注意事項を記載しています。
※ 筆者は法律に関する資格を持たないので、この見解が正しいとは限りません。法的な問題については必ず専門家の意見をお聞き下さい。
▫ モデルディスクリプション
モデルディスクリプション(モデルページの説明文)を確認するには、以下のように『Show More』をクリックしてください。

すると、以下のようなモデルに関する説明文が表示されます。
推奨されるプロンプトや設定などの説明文が記載されていることがあります。
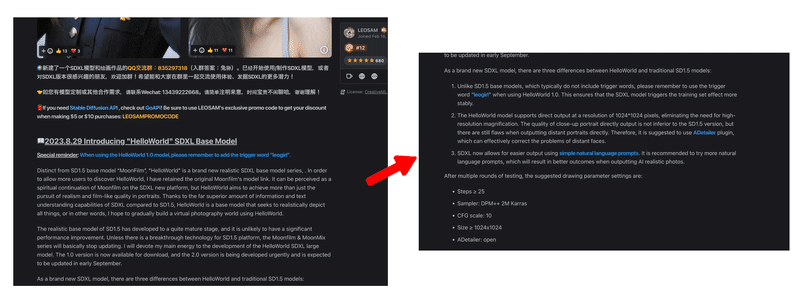
こちらのモデルでは、以下が記載・推奨されています。
トリガーワード「leogirl」を使用するとSDXLモデルがトレーニングセット効果が安定的に発揮され、画像の品質が上がりやすいこと。
1024×1024ピクセルの解像度での直接出力をサポートしているため、高解像度の拡大が不要であること。
遠景ポートレートなどの画像出力にはまだ欠点があるため、出力する際は顔をを効果的に補正できるADetailerプラグインを使用すること。
リアルな画像を出力する際は、自然言語(単語ではなく、文章のようなもの)を使用して出力すること。
例:「photo of a japanese girl, space ship」(日本人の女の子の写真、宇宙船)Step数を25以上にすること。
Smpler(サンプリングメソッド)を DPM++ 2M Karras にすること。
CFGスケール を 10 にすること。
サイズ を 1024x1024 以上にすること。
ADetailer を使用すること。
また、更に下にスクロールするとユーザーからの意見やコメントが見られるので、使い方の参考になります。以下のように、翻訳ツールを使用して確認することもできます。
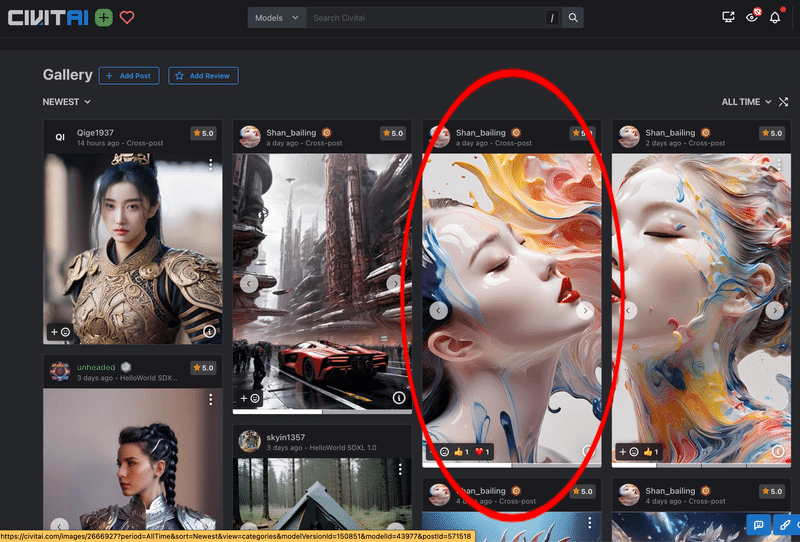
また、更に下にスクロールすると以下のようにGallery が表示され、ユーザーによって生成された画像の一覧が表示されます。
好きな画像をクリックすると、詳細を確認できるので、今回は以下の◯で囲っている画像の詳細を確認します。
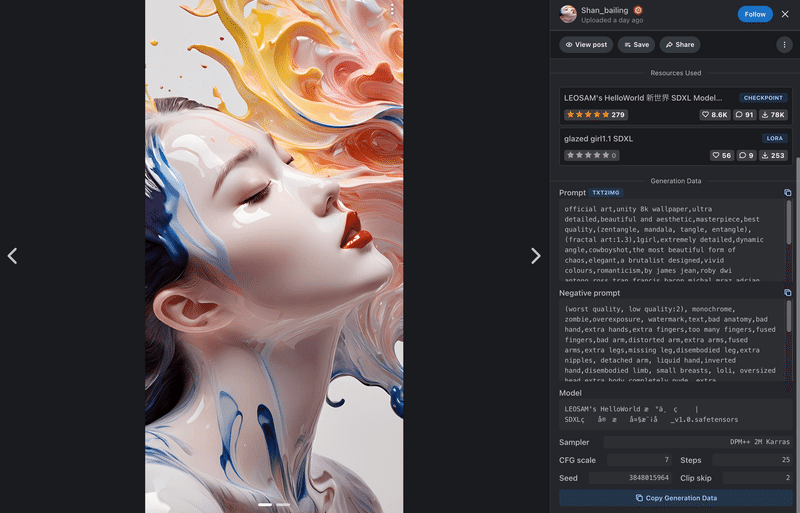
以下のように、画像生成に使用した LoRA、Prompt、Negative Prompt、Model、Sampler、CFG Scale、Step数、Seed、Clipt skip などが確認できます。
HuggingFace
「HuggingFace」は、機械学習のモデルやデータを共有できるウェブサイトです。最新の技術や情報がたくさんあるのが特徴です。技術者や研究者などがよく使っています。
サイトは以下になります。
▫ モデルを探す方法
HuggingFace でモデルを探すには、まず上部メニューの『Model』を選択します。すると、様々なモデルの一覧が表示されます。
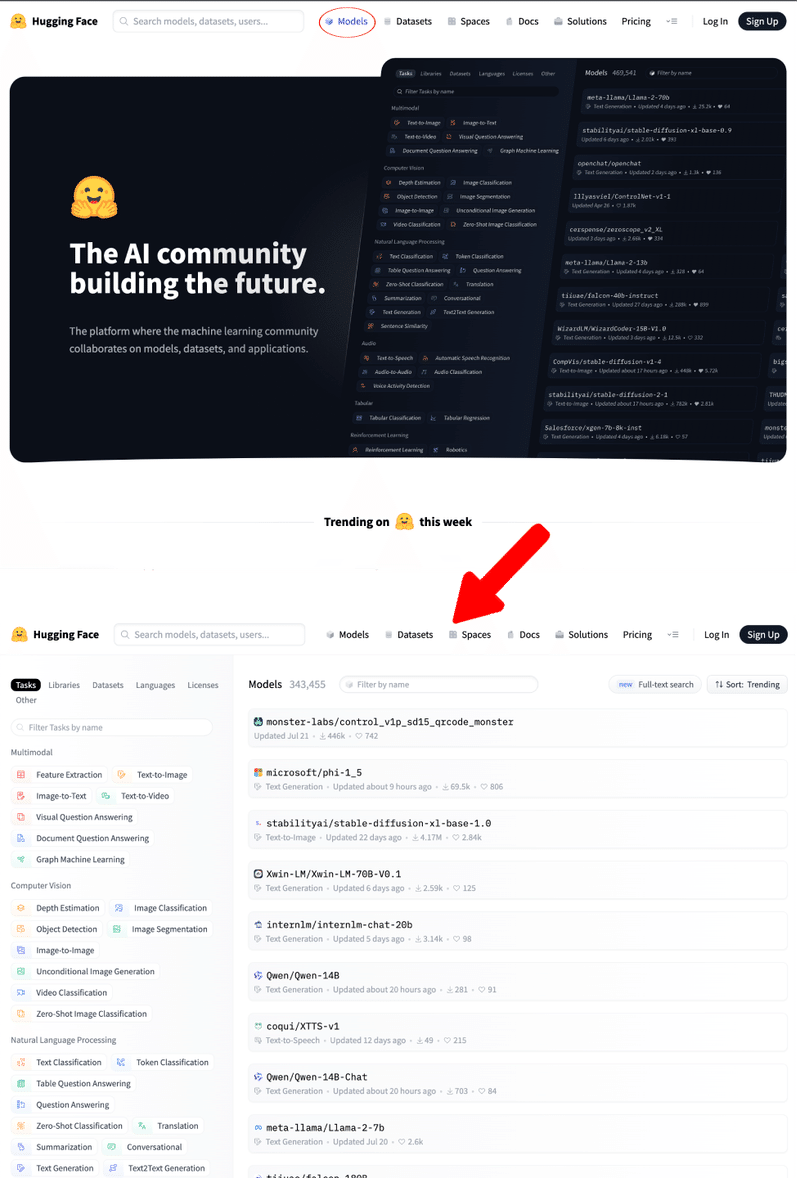
この中から絞り込みを行っていきます。
『Tasks → Text-to-Image』とクリックしてモデルを絞り込みます。
Lecenses の欄は、先程の CreativeML Open RAIL-M を使用するので
『Lecenses → CreativeML Open RAIL-M』とクリックします。

すると、以下のように絞り込まれるので『Sort:Trending』と選択して、検索窓に『SDXL』と入力します。
他にも、以下のようなもので検索結果をソートできます。
Most Download:ダウンロードされた数順
Recently Update:更新日順
Most Likes:「いいね」の数順
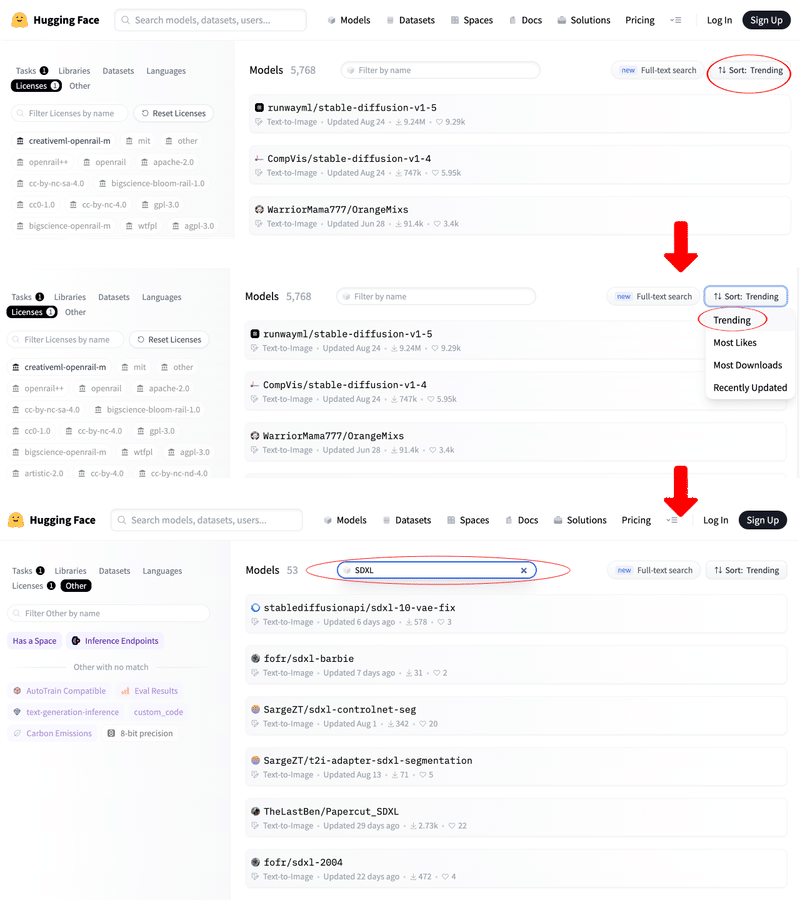
このようにして、Model や LoRA を検索することができます。
▫ Model Card
HuggingFace のモデルには、以下のようにModel Card と呼ばれる詳細欄があります。
CivitAI と同様、こちらでモデルの推奨プロンプトや詳細情報、ライセンスなどを確認できます。
今回は以下の Model Card を見てみます。
以下のような画面が表示されます。
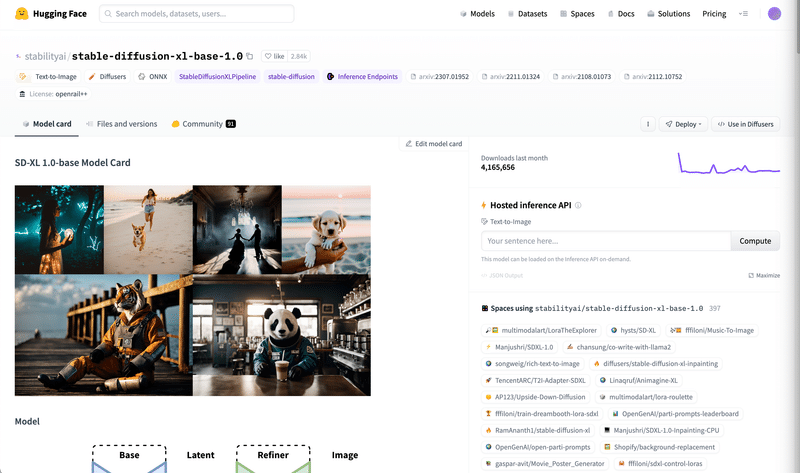
翻訳して下にスクロールすると、以下のような説明や制限が書いてあります。
この部分はCivitAI と同様、推奨設定や制限事項などが記載されている場合が多いので、使用する前に必ず確認してください。

▫ モデルのライセンス
このモデルのライセンスは『CreativeML Open RAIL-M ライセンス』ですが、以下で確認できます。
また、『License:openrail++』をクリックして、ライセンスの詳細も見ることが可能です。
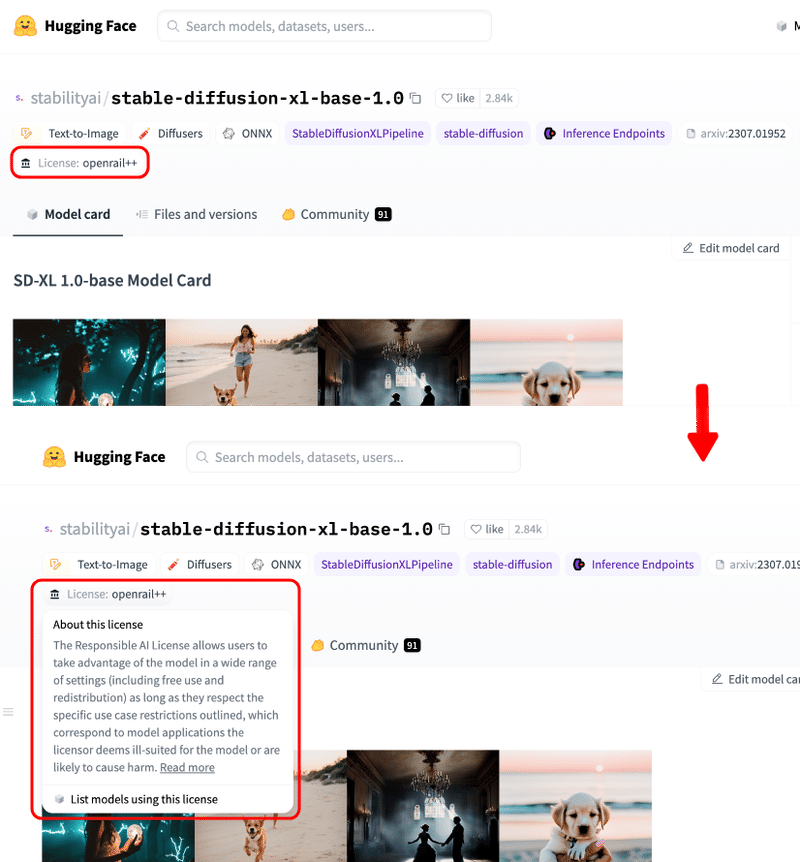
ライセンスの詳細は下記になります。
各モデルのダウンロード先
こちらのチャプターでは、HuggingFaceやCivitAIを使用して、モデルを探す方法やモデルの詳細を確認する方法を解説してきました。
ここでは、実際にStable Diffusion WebUI でそれぞれのモデルをダウンロードする際の保存先について、 おさらいしていきます。
▫ Checkpoints (学習モデル)
こちらは『<Stable Diffusion WebUIのフォルダ>/models/Stable-diffusion』のパスにダウンロードします。
▫ VAE
こちらは『<Stable Diffusion WebUIのフォルダ>/models/VAE』のパスにダウンロードします。
▫ Textual inversion (Embeddings)
こちらは『<Stable Diffusion WebUIのフォルダ>/embeddings』のパスにダウンロードします。
▫ Hypernetworks
こちらは『<Stable Diffusion WebUIのフォルダ>/models/hypernetworks』のパスにダウンロードします。
▫ LoRA
こちらは『<Stable Diffusion WebUIのフォルダ>/models/Lora』のパスにダウンロードします。
● 画像生成AIでやってはいけないこと
画像生成AIは、素晴らしい技術ですが、悪用される可能性もあります。画像生成AIでやってはいけないことは以下の通りです。
人権侵害:他人の肖像権やプライバシーを侵害するような画像を生成したり、公開したりしないでください。例えば、特定の人物の顔や体を加工したり、不適切なシチュエーションに置いたりしないでください。
著作権侵害:他人の著作物や知的財産権を侵害するような画像を生成したり、公開したりしないでください。例えば、既存のアニメや漫画やゲームなどのキャラクターや世界観を無断で使用したり、模倣したりしないでください。
法令違反:法律や条例や規則などに違反するような画像を生成したり、公開したりしないでください。例えば、暴力や犯罪や差別や児童ポルノなどの画像を生成したり、公開したりしないでください。
画像生成AIで作った画像で他人に迷惑をかけたり、損害を与えたりしないように注意してください。
● おわりに
以上で本稿の解説を終了します。ご質問・ご感想等はコメント欄までお願いします。
今後も生成AIに関する記事を投稿していく予定ですので、フォロー・いいね をいただけると非常に励みになります。
また、私のプロフィール記事に関してもご一読いただけると助かります。
私の他の投稿に関しては、以下のリンクからメンバーシップに加入すると全て無料で読み放題になりますので、是非読み漁って生成AI の魅力を体験してみてください。
また、生成環境の心臓部である『RTX4090(¥358,800)』を購入するため、下記のリンクからご支援いただけますと幸いです。
ここまでご覧いただきありがとうございました。 それでは、充実した生成AIライフをお楽しみください。
この記事が気に入ったらサポートをしてみませんか?