

記事一覧


LLama2の訓練可能な全層をQLoRAで学習する
はじめにLLama2はMetaが23年7月に公開した、GPT-3に匹敵するレベルのオープンソース大規模言語モデル(LLM)です。
最近はFalcon 180bのような、より大きなモデルも出ていますが、デファクトスタンダードとして定着している感があります
LLMに新たな情報を加える手法として、ファインチューニング、特にQLoRAが注目されています。
しかしQLoRA、特に初期設定では一部のパラ

LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動
Llama2-70b-chatで専門テキスト(学会の予稿集)をファインチューニング(QLoRA)
概要23年8月時点におけるオープンソース大規模言語モデルの筆頭とも言えるLlama2を使い、専門テキストをファインチューニングした際のメモです。
言語モデルに知識を追加するのは、意外と難しいということがわかりました。
前提となるコード類は以下の記事などを参照
学習データ筆者が所属している学会の一つである、高分子学会の年次大会(2023年)の予稿集を学習させてみることにしました。
(学会の参加者
llama2のファインチューニング(QLORA)のメモ
2023/11/13追記
以下の記事は、Llama2が公開されて数日後に書いた内容です。
公開から数ヶ月経った23年11月時点では、諸々の洗練された方法が出てきていますので、そちらも参照されることをおすすめします。
(以下、元記事です)
話題のLamma2をファインチューニングします。
QLoRAライブラリを使うパターンと、公式推奨の2つを試しました。前者が個人的にはオススメです。
前提H
llama2のセットアップメモ (ダウンロードと推論)
話題のモデルのセットアップ
Llama2とは商用利用が可能(諸説あり)で、GPT3並の性能を持つ、オープンソースモデルの本命です(2023/7/19時点)
利用方法
いくつかあります
手段1 Metaの公式モデルを使う
登録必要
あまり使いやすくない印象です
13b以上は、GPU並列利用が基本(?)
手段2 Hugging faceの公式連携モデルを使う
登録必要
便利です


airoboros: GPT-4で作成した学習データで微調整した大規模言語モデル(ほぼgpt-3.5-turbo)
Self-Instructの手法でGPT-4を使用して生成された学習データを使って、ファインチューニングされたLlaMA-13b/7bモデルが公表されていました。
モデルの概要Self-Instructの手法でgpt-4、またはgpt-3.5-turboを用いて、人間が生成したシードを含まず学習データセットを作成(OpenAIライセンスの対象)
airoboros-gpt4
airoboro


rinna-3.6Bをオリジナル小説でLoRAファインチューニングしてみた【RTX3060 (VRAM 12GB)】
動作確認のために、お試しでやってみました。
概要背景
AITuberを含めた創作活動への活用のためにrinna-3.6Bでのファインチューニングを勉強したかったのですが、せっかくなら持ってるRTX3060を使ってローカルでやりたいと思っていました。
偉大なる先駆者の方々によって方法が開拓されていたので、ありがたく参考にさせていただいた次第です。
本記事でやったこと
・ローカルのRTX30



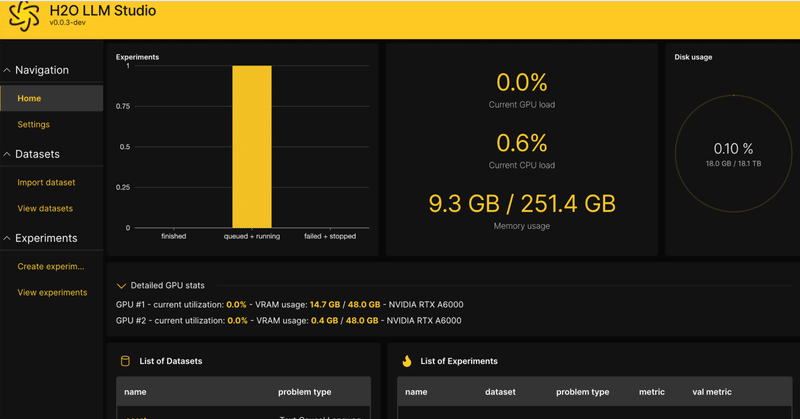
H20 LLM Studioを試す
H2O LLM Studioというのが、要するにLLM版Automatic1111みたいな、要はWebUIとして最高でございますという話だったので使ってみた。
インストールは超簡単。
ただ、CSV形式じゃないと学習データに使えないっぽいのでそこの使い勝手があまり良くないかな。最近の流行はJSONL形式だしね
あと、仕方ないのかもしれないが設定できる項目が多すぎて目が回りそうになる。
まあで
LLM の LoRA / RLHF によるファインチューニング用のツールキットまとめ
「LLM」の「LoRA」「RLHF」によるファインチューニング用のツールキットをまとめました。
1. PEFT「PEFT」は、モデルの全体のファインチューニングなしに、事前学習済みの言語モデルをさまざまな下流タスクに適応させることができるパッケージです。
現在サポートしている手法は、次の4つです。
◎ LLaMA + LoRA
「Alpaca-LoRA」は、「LLaMA」に「LoRA」を適用


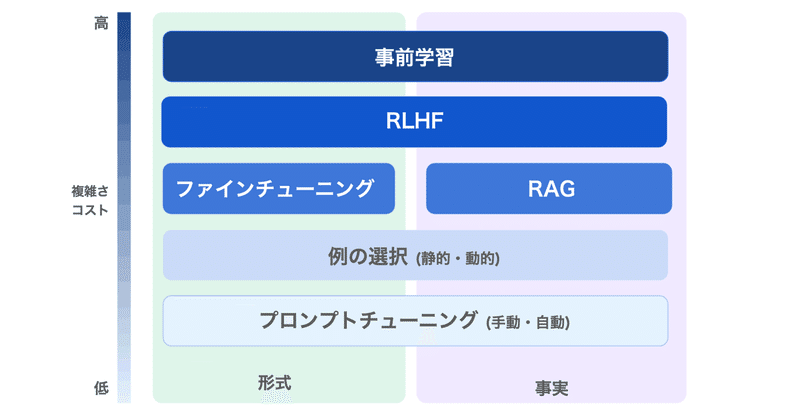
GPT/LLMモデルの進化!追加の知識を組み込む最新テクニック
OpenAIの範囲外の話題でも、オープンソースコミュニティの作業を見ることができます。LLMに知識を追加するには、fine-tuningを使用することができます。OpenAIはfine-tune APIを提供していますが、LLM関連のオープンソースコミュニティの作業に少し調査レポートしました。関連情報を共有します。
fine-tuning以外のオプションStanfordのLLaMAに基づくAlp
